CMPUT 229 - Computer Organization and Architecture I
Lab 6: Perceptron Based Branch Predictor
Creator: Sarah Thomson
Introduction
Branch prediction is a widely researched technique in computer architecture that is used to improve the performance of instruction pipelines in processors. By predicting the outcome of a branch instruction, the processor can decide which path of execution to follow before the actual outcome is known. Branch prediction minimizes stalls and pipeline bubbles caused by control hazards, and improves overall processor performance.
In this lab, you will develop a perceptron-based branch predictor simulator using RISC-V and the RARS simulator. Your simulator will:
- Predict Branch Outcomes: For each branch instruction in a provided RISC-V function, your simulator will use a perceptron to predict whether the branch will be taken or not.
- Train the Predictor: After each branch instruction's outcome is known, the simulator will use the actual outcome to train the perceptron, updating its weights to improve future predictions.
- Track Accuracy: The simulator will collect statistics on the accuracy of its predictions throughout the execution of the input function.
Inspiration and References
Dynamic Branch Prediction with Perceptrons is a paper authored by Daniel A. Jimenez and Calvin Lin from The University of Texas at Austin. This paper, as well as work done by Quinn Pham (former CMPUT 229 student) from the University of Alberta are the inspirations and foundations of this lab.
Background
Branch Prediction
Branch prediction is extremely important in increasing the performance of a processor by avoiding control hazards. There are two main types of branch prediction: static and dynamic. With static branch prediction the prediction is made independent of the past outcome of the current or other branches. For instance, all predictions are made based on the direction of the branch: backward branches are predicted taken and forward branches are predicted not taken. A static predictor is unable to learn and adapt. A dynamic branch predictor uses special hardware components to store branch related data in order to make predictions based on real runtime data. For example, a processor may be equipped with a branch pattern history table that stores branch outcome data during a program’s execution that the processor can use to make predictions. The perceptron based branch predictor is an example of a dynamic branch predictor.
Here is a simple example of a dynamic branch predictor that uses a Pattern History Table (PHT) full of one-bit saturating counters to predict branches (a saturating counter is a value that can be incremented or decremented within a fixed range, and once it reaches either end of this range, it "saturates" or stops incrementing or decrementing.) In the fetch stage of the execution of a branch instruction, the predicted branch outcome is looked up in the PHT using the branch PC as the index. The processor will either speculatively take the branch (counter == 1), or not take the branch (counter == 0). All dynamic branch predictors must have a feedback mechanism that updates the prediction after the true branch outcome is determined. For example, if a branch was predicted to not be taken, but was actually taken, its corresponding counter will be updated from 0 to 1 in the PHT. This example predictor is not extremely accurate, as using only the previous outcome of a branch to predict the next outcome does not allow the predictions to be based on much context of the program state. It is known as a local predictor because it only considers the history of the individual branch that it is predicting.
On the other hand, a global predictor uses history of all recent branches to predict the of a given branch. The global branch history is stored in a hardware structure known as the Global Shift Register (GSR). The GSR in the example video below stores the outcomes of the last eight executions of branches throughout the program.
This pattern of recent branch outcomes is then used to index into the PHT. The PHT in this example contains a 1-bit saturating counter for each possible pattern represented by the shift register. For a 8-bit shift register, this means that each branch will have 28 entries in the PHT, one for each possible combination of the recent branch outcomes (1 == branch taken, 0== branch not taken).
Perceptron Based Branch Predictor
The perceptron branch predictor uses both local and global branch history, and is able to learn significatly more complex patterns than the previous two examples.

The RISC-V code above includes a branch whose outcome
depends on the outcomes of previous branches. The branch
instruction beq t0, t1, branch_taken will only be
taken if t0 is set to 10. However,
t0 is set to 10 only if the earlier branch
beq a0, zero, set_value is taken. If this
function is executed thousands of times within a program (for
whatever reason), recognizing that the outcome of beq
a0, zero, set_value affects later branches is very
important.
Why Perceptrons?
Perceptrons are one of the simplests forms of neural networks and are used as binary classifiers. They can learn to recognize patterns in data; given an input, a perceptron classifies it into one of two categories. Through supervised learning --- training a model using (input, actual output) pairs, a perceptron can learn to predict outcomes with a high level of confidence over time. Also, due to their simplicity, perceptrons are relatively low-cost to implement. As an overview, a perceptron takes a set of input values and uses its weights and bias to choose between two outcomes (taken or not taken). Each input represents one feature of the input data to be classified. The weights are parameters that determine the importance of each input to the output. They are updated during training. The perceptron calculates a weighted sum of the inputs and applies an activation function to determine the output. in a perceptron-based branch predictor, percpectrons can learn how patterns in branch history affect the outcome of a given branch.
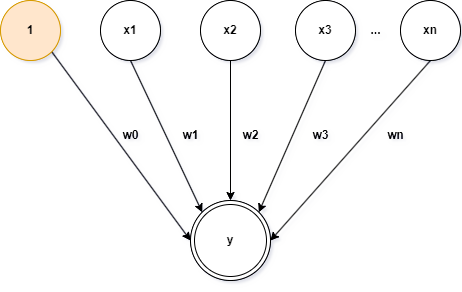
Below is a diagram illustrating a perceptron. The x values represent the input vector, and the w values represent the weight vectors. y
represents the weighted sum output. The first input value x0 will always be set to 1 in order
to learn the bias of the current branch independently of previous branches.
Perceptron learning involves two stages: prediction and training. During the prediction stage, the perceptron calculates a dot product between the input vector and the weight vector. The output of this calculation is then passed through an activation function to make a binary prediction. The activation function used in this lab is very simple: if the output is greater than or equal to zero, the branch is predicted to be taken. If the output is less than zero, the branch is predicted to be not taken.
In a perceptron-based branch predictor, the PHT stores a set of weights instead of saturating counters. The branch PC is used to index into the PHT. Each branch PC has an associated set of weights stored in the PHT. The bits of the GSR are used as the input features. Taking the dot product of the input vector (GSR) and a branch's weight vector measures their alignment. A large positive dot product indicates that the global history register vector is pointing in a similar direction to the weight vector, suggesting that the branch is likely to be taken. A negative dot product implies the input vector is aligned in the opposite direction, indicating the branch is less likely to be taken. If the dot product is zero or small, it suggests little correlation between the input vector and the weight vector.
Dot Product
Mathematically, a dot product is the sum of the products of the corresponding components of two vectors. The dot product takes two vectors as inputs and returns a single scalar value. The purpose of the dot product is to determine how much the direction of one vector aligns with the direction of another.
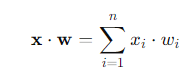
Training Perceptrons
After the actual outcome of a branch is known, a perceptron compares the prediction to the actual outcome, and updates the weights if training conditions are met. Changing the weights during training affects the influence of each input on the final output. The actual result is used to make adjustments to the weights. By repeatedly training with actual results, the perceptron improves at distinguishing between different input patterns. Without using actual results, the perceptron would have no reference point for what the correct output should be, making it impossible to learn anything.
Here is the algorithm used to train a perceptron predictor, provided by Dynamic Branch Prediction with Perceptrons
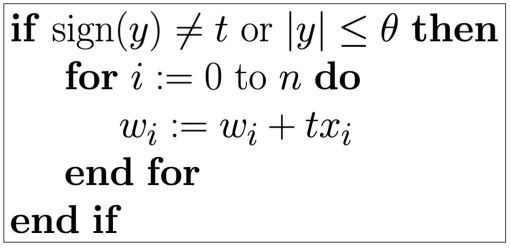
Where y is the output of the perceptron; t==1
if the actual outcome of the branch was taken and t==-1
if the outcome is not taken; θ is a threshold that determines
when enough training is done; xi is a bit
that indicates the outcome of the ith bit in the GSR
(1 for taken and -1 for not taken); and wi is the
weight
For a perceptron to undergo training either of the two conditions must be met:
- The prediction was incorrect. Training is needed if the sign of the predicted output differs from the sign of the actual output.
- The confidence is low. The perceptron continues to train until its output reaches the threshold θ. If the output exceeds this threshold (indicating high confidence in its predictions), further training is not necessary.
Intuitively, when training for a particular branch whose outcome is correlated with the outcomes of previous branches, if the same pattern of previous branch outcomes consistently appears in the global history register, the corresponding weights will be adjusted in the same direction each time. Over many executions of this branch, given the same global-history register input the dot product's magnitude will increase either positively or negatively. The increase of the dot product’s magnitude means the predictor is growing more confident in its predictions.
If the branch outcome is not correlated with the outcome of previous branches, then the global-history register is fairly random each time a certain branch is taken, the weights will not increase much in any particular direction, and the dot product between the weights for this branch and the global history register will be close to zero.
Here is a basic overview of the components of a perceptron and how they apply to the lab:
| Name | Variable | Description | Lab Specifics |
|---|---|---|---|
| Input | x = [x1, x2, x3, ..., xn] | Each element in an input vector represents one feature of the data to be classified. | Each element of the input represents one bit of the global shift register at the time of making a prediction. This lab uses an 8-bit global shift register. (x0 is left out because x0 is always set to 1 so that the perceptron can learn the bias of the branch independent of history. This is explained further down.) |
| Weights | w = [w0, w1, w2, ..., wn] | Weights are parameters that determine the importance of each input to the output; they are updated frequently during training as the perceptron learns. | Each branch instruction is associated with an array of weights. Each weight represents the influence that the corresponding bit in the input vector has on the branch's predicted outcome. For instance, a large weight w1 indicates that the outcome of the most recent branch, represented by x1, is strongly correlated with the outcome of the current branch being predicted. |
| Output | y | A dot product is performed on the input values and weights, resulting in a weighted sum. | The output is the result of taking the dot product of the global shift register bits and the weights for a branch. The prediction is the sign of the outcome. A large positive output indicates confidence that the branch will be taken. A large negative output indicates confidence that the branch will not be taken. Outputs close to zero represent low-confidence predictions. |
| Actual Branch Outcome | t | Once the actual outcome of the branch (taken or not taken) is known, it is provided to the perceptron to compare against its prediction. If there's a difference, the perceptron updates its weights during training to improve future accuracy. | This is the actual outcome of the branch, determined after the conditional statement is evaluated during the execution of the instruction. |
| Threshold | θ | A constant value used in training to determine when to stop training a perceptron. | This is set to 127 in this lab. |
Below is an example of how to make predictions and train a perceptron.
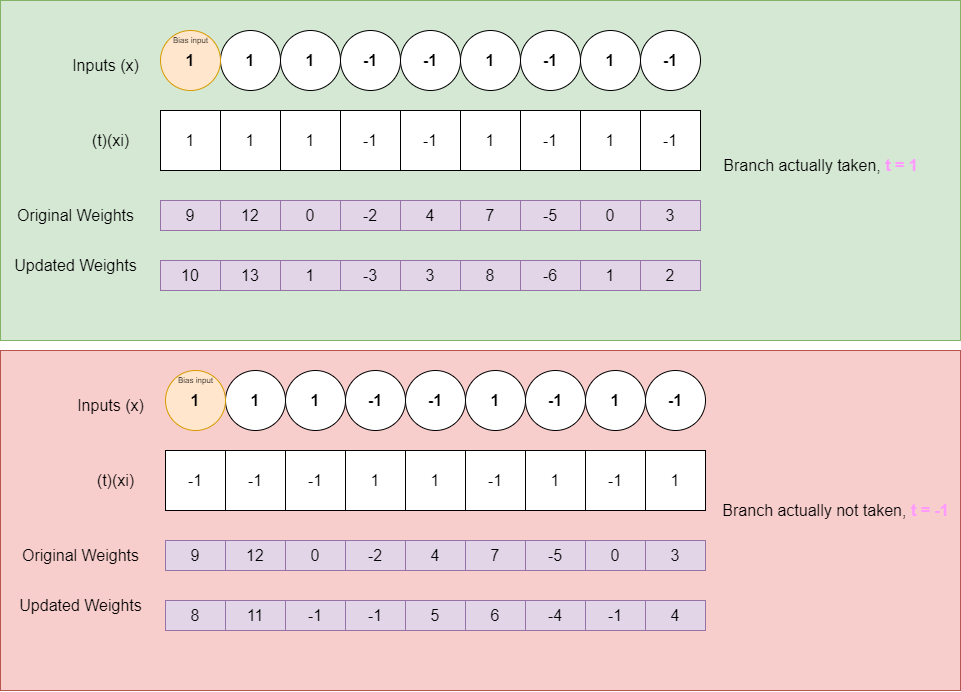
Consider the branch predictor predicting the outcome of of a branch with the associated weights [9,12,0,-2,4,7,-5,0,3]. First, the bits of the global shift register are converted to signed values: 1 for a branch taken and -1 for a branch not taken. Next, the dot product between the input vector and the corresponding weight vector is calculated. Keep in mind that the first input value is always 1 (representing the bias term), and the remaining eight values come from the global shift register.
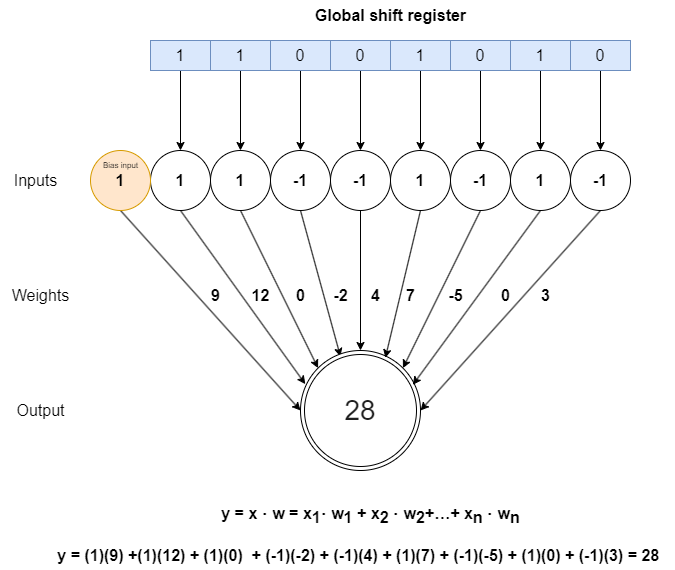
As shown in the diagram, in this case the predicted outcome is 28. Let's consider the two possible actual outcomes:
- The branch outcome
taken: The prediction is correct. The algorithm checks if the output is less than or equal to the threshold value. Since 28 is less than the threshold of 127, this condition is met, and the perceptron will continue training to increase its confidence in future predictions. - The branch outcome is
not taken: The prediction is incorrect. In this case, the algorithm will undergo further training to adjust for the incorrect prediction.
Assignment
The goal of this lab is to build a perceptron-based branch predictor simulator in RISC-V. This simulator will take a RISC-V function as input and execute that function using data structures that simulate the hardware required for a perceptron-based branch predictor. Before each branch instruction in the input file is executed, the simulator will make a prediction. After the outcome of the branch instruction is determined, the perceptron weights for that branch may be updated according to the training algorithm. Throughout the execution of the input program, the simulator tracks statistics about the accuracy of the branch predictor. These statistics are printed once execution is complete.
This lab uses an 8-bit global shift register, and assumes that
each branch has a unique entry in the pattern history table (PHT);
this simplifies the indexing process by removing the need to
implement a hash function to access the PHT. Branches are not
identified by their PC in this lab, instead each branch should be
assigned a unique branch Id. The branch ids correspond to the
static relative position of the branch in the code --- it is not
the order in which the branches are executed at runtime. For
example, if there are n branch instructions in an
input function, the first branch instruction that appears in the
binary function encoding should be assigned Id = 0,
and the last branch should be assigned Id = n-1.
This lab is organized into two stages:
1. Instrumentation Stage
The instrumentation stage
prepares the original function to be compatible with the branch
predictor. To be compatible with the branch predictor, two
functions defined in perceptron_predictor.s must be
called each time a branch is executed: makePrediction
and trainPredictor. makePrediction
predicts the branch outcome, and trainPredictor
trains the perceptron based on the actual branch outcome.
The original code of the input function does not contain these calls. Executing this function without modification will not capture its branch information. The solution to this lab uses a compiler technique known as instrumentation, which involves inserting additional code (such as specific function calls) into a program. Instrumentation typically collects data about a program's execution, such as performance metrics, profiling information, or debugging details. In this lab, the instrumentation will collect branch information.
There are three different sequences of instructions to instrument into the original code:
- Prediction setup - inserted immediately before every
branch instruction to call to
makePrediction. - Prediction resolve fallthrough - inserted immediately
after every branch instruction to call to
trainPredictorto indicate that the branch was not taken. - Prediction resolve target - inserted immediately before
the target instruction of a branch a call to
trainPredictorto indicate the branch was actually taken.
2. Execution Stage
Once calls to
makePrediction and trainPredictor have
been correctly instrumented into the original function, the
modified input function can be executed. The modified function
is executed under the supervision of the branch predictor. This
stage includes jumping between the modified code,
makePrediction, and trainPredictor
frequently, and they must be able to communicate about the state
of the program and the state of the predictor. They will do so
with the help of the global variables described in the Global
Variables and Data Structures section below.
The lab flow follows the following steps:
- Analyze the input function: analyze the original input function code and fill in some of the data structures described below.
- Instrument the input function: Copy the instructions of the original function into a new array and insert the function call code into their correct spots. You will also need to adjust some branch and jump offsets in the new function to account for the added code; this is described further down.
- Execute the modified function jump to the start of the new function, where the branch predictor simulator will start working.
Self-Modifying Code
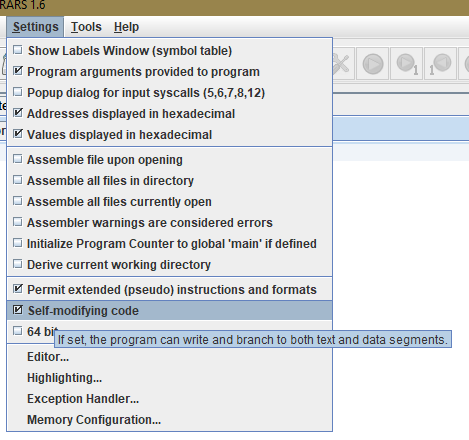
The solution for this lab executes a function that is being modified during its execution. Thus, it belongs to a class of program known as self-modifying code, where a program may alter its own instructions after it has started executing.
To enable self modifying code in RARS, check the Self-modifying code box under the Settings tab located at the top left corner of RARS.
perceptron_predictor.s takes a path to a RISC-V function binary file as a program argument.
When the binary file is passed as a program argument to your solution file (perceptron_predictor.s), the provided common.s
file will parse each instruction into an array called originalInstructionArray that is pre-declared in the .data section. Before the instrumentation stage,
there will be no way to predict the branches in the original program when it executes, or to analyze their actual outcomes. The original code will have to be modified to
be able to work with the perceptron branch predictor during the instrumentation phase.
After completing the instrumentation stage, the modified version of the input function should be stored in an array called
modifiedInstructionArray. This array will include the necessary function calls to supply data to the
predictor simulator in real time as the modified function executes. With the self-modifying code feature enabled, your program can jump to the starting address of modifiedInstructionArray
in the .data section of memory and begin executing the instructions stored within it.
Below is a code snippet that demonstrates how to jump to the first instruction in modifiedInstructionArray:
la t0, modifiedInstructionsArray jalr t0
Global Variables and Data Structures
Pay close attention to the custom data structures and global variables outlined below because parsing/constructing them properly is essential.
Memory for some of these data structures is allocated and
initialized in the common.s file. Pointers to these
data structures are passed to the primary function
(perceptronPredictor) in your solution file
perceptron_predictor.s.
Memory for the rest of the data structures is initialized in
the starter code for the perceptron_predictor.s file.
These structures can therefore be treated as global variables
whose addresses can be loaded from anywhere in the program. The
design of this lab globally allocated these structures to
lower the number of instructions required for
the instrumentation stage by reducing the number of arguments
makePrediction and trainPredictor require.
You are free to add other global variables and data structures if necessary. You must correctly utilize the provided ones. Be careful because we will test each function in your solution independently. Thus you should not create global variables that are used between functions.
Always remember to add a sentinel value at the end of the data structures that require it.
Data Structures for Instrumentation Stage
These data structures need to be used/filled in the
instrumentation stage in order to prepare the input function for
the execution stage. These data structures are all allocated in
common.s and passed as arguments to your solution
file's primary function.
Description: An array that contains every instruction from the input function. Each element is a one word long binary representation of an instruction. This array ends with a sentinel value of -1 (0xFFFFFFFF).
In this lab, input functions are represented as an array of
RISC-V instructions. Every RISC-V instruction can be represented
as a word in memory (e.g., addi t1, t1, 1 =
0x00130313). Thus, a function can be represented as an array of
32-bit words. This array is filled by common.s and passed
as an argument to your solution file's primary function
perceptronPredictor.
Description: An array that contains the input function instructions after the insertion of the function calls during instrumentation. Each element is a one 32-bit word containing the binary representation of an instruction. This array ends with a sentinel value of -1 (0xFFFFFFFF).
The base of this array is where program execution will jump to for running the perceptron-predictor simulator. Memory
for this array is allocated in common.s; this empty array is passed as an argument to your solution file's primary function perceptronPredictor.
Description:
A byte array where each byte acts as an indicator that a specific sequence of
instructions must be inserted into modifiedInstructionsArray. Each byte in
this array corresponds directly to an instruction in the originalInstructionsArray
at the same index.
The indicators are as follows:
1 - The instruction is a branch.
2 - The instruction is a target.
3 - The instruction is a branch that is also a target
0 - The instruction is anything else
Ends with a sentinel value of -1 (0xFF).
Memory
for this array is allocated in common.s; this empty array is passed as an argument to your solution file's primary function perceptronPredictor.
Description: An array of 32-bit words. Each word in this array corresponds directly to an instruction in the originalInstructionsArray at the same index. Each word specifies the total number of instructions to insert before the corresponding instruction in the originalInstructionsArray. Ends with a sentinel value of -1 (0xFFFFFFFF).
This array is useful when adjusting the branch and jump relative offsets when inserting new instructions into the function. Memory
for this array is allocated in common.s; this empty array is passed as an argument to your solution file's primary function perceptronPredictor.
Data Structures for Execution Stage
These data structures need to be used/filled in the execution stage in order to correctly run the predictor simulator. These data structures are all
allocated in perceptron_predictor.s and are global variables.
Description: This is a 1-byte global variable. Each bit in globalShiftRegister corresponds to a previously taken branch. The most significant bit of globalShiftRegister is the most recently executed branch instruction; After the outcome of a branch is determined, the globalHistoryRegister should be shifted one bit to the right and the new branch outcome (either 1 or 0) should be placed in the most-significant bit of the byte. The globalHistoryRegister will be initialized so that every bit is zero (the branch predictor assumes that no branches have been taken recently) before the input function executes.
Description: This global variable is an array of words that simulates a pattern history table. Each element is a pointer to the 9-byte long array of perceptron weights for the corresponding branch id. For example, the first element holds a pointer to the weights for the branch instruction with branch id = 0, the second element holds a pointer to the weights of the branch instruction with branch id = 1, and so on. Ends with a sentinel value of -1 (0xFFFFFFFF).
Note: Since it is unknown how many branches are in the input function before runtime, The weight arrays should be dynamically allocated after the function analysis had determined how many branches the function has.
Dynamic memory allocation is useful in such cases where the maximum size or bounds of a data structure are unknown.
Using dynamic memory allocation, you can calculate the amount of space that your data requires, allocate that amount of memory on the heap, and then store your data.
Use the sbrk ecall (code 9) in RARS to allocate heap memory. Set a0 (argument for the ecall) to the amount of memory in bytes, and the address
of the allocated block will be returned in a0. For more details, visit the RARS Environment Calls page.
Description: These are each an array of nine bytes. They must be dynamically allocated at runtime because the number of perceptrons are dependent on the number of branch instructions in the input file, and each branch instruction needs its own perceptron weight array. Bytes 1-8 are associated with bits 0-7 of the globalShiftRegister, and byte 0 is associated with the bias input. Every weight should be initialized to zero upon allocation. Does not end in a sentinel.
Description: This is a single word global variable that stores the output of the most recent branch prediction output. It is the result of taking the dot product of the global shift register bits and the weights.
Description: This is 1-byte global-variable; it is set to 127 by default, do not modify it.
Description: This is a 1-byte global variable. This variable represents the branch Id of a branch that has just been setup with a predicted output but has not yet been resolved with the actual outcome. If there is no unresolved branch at the moment, the variable is set to -1. The variable should be set immediately before making a prediction for a branch and should be reset to -1 after the actual branch outcome is determined and any necessary training is completed.
Description: This is a single word global variable. This variable can be used to hold the total number of branch instructions in the input program.
Description: This is a single word global variable. This variable gets updated every time a prediction is made for a branch, so that it counts the number of total branches executed while the input function is executing. This is used to print statistics after the input function is done executing.
Description: This is a single-word global variable. This variable gets updated during training if the prediction aligns with the actual outcome of a branch. This is used to print statistics after the input function is done executing.
Instrumentation
The perceptron_predictor.s starter file provided contains generator functions that create the setup, resolve fallthrough, and resolve target instructions for the instrumentation stage. These generators create three different templates that you can insert into your modified function as required. The three templates are as follows:
- Prediction setup template: The instructions in this
template are intended to be executed immediately before each
branch instruction. The template includes seven
instructions that are used to prepare the branch information
required by the
makePredictionfunction, and then jump to themakePredictionfunction. BRANCH ID is passed as an argument tomakePredictionand is also stored into theactiveBranchglobal variable to communicate that the branch prediction process is in progress for that branch. The input function is provided to the solution file as an assembled binary. Thus the new instructions required for instrumentation must be inserted into the original function as their assembled binary encodings. This means that labels must be deconstructed into their absolute addresses, and values stored in global variables or registers must be converted to immediates. - Prediction resolve fallthrough template: This template includes four instructions that are used to call the trainPredictor function. It also passes trainPredictor '0' as an argument to indicate that the branch fell through (was not taken). This template should be inserted immediately after each branch instruction from the original function.
- Prediction resolve target template: Similar to the resolve
fallthrough template, this template includes four
instructions that are used to call the trainPredictor function. The
two key differences between this and the resolve target template is
that this template passes a '1' as an argument to trainPredictor,
indicating that the branch was taken, and that this template must be
placed immediately before any target instructions from any/all of the
branches in the input program.
addi a0, a0, 1 # indicate branch taken lui t0, trainPredictor[31:12] # provide upper half of the absolute address of the trainPredictor label addi t0, t0, trainPredictor[11:0] # provide lower half of the absolute address of the trainPredictor label jalr t0 # jump to trainPredictor label
addi a0, zero, BRANCH ID # move the branch id of this instruction into an argument lui a1, a1, activeBranch[31:12] # provide upper half of the absolute address of the activeBranch global variable addi a1, zero, activeBranch[11:0] # provide lower half of the absolute address of the activeBranch global variable sw a0, 0(a1) # store the branch id to the active_branch global variable lui t0, makePrediction[31:12] # provide upper half of the absolute address of the makePrediction label addi t0, t0, makePrediction[11:0] # provide lower half of the absolute address of the makePrediction label jalr t0 # jump to make_prediction label
addi a0, a0, 0 # indicate branch not taken lui t0, trainPredictor[31:12] # provide upper half of the absolute address of the trainPredictor label addi t0, t0, trainPredictor[11:0] # provide lower half of the absolute address of the trainPredictor label jalr t0 # jump to trainPredictor label
Here are examples of what the instrumentation data structures
should look like using the demo function as an input
function:
demo: originalInstructionsArray: instructionIndicatorsArray: numPriorInsertionsArray:
addi sp, sp, -20 0xfec10113 0 0
sw s0, 0(sp) 0x00812023 0 0
sw s1, 4(sp) 0x00912223 0 0
sw s2, 8(sp) 0x01212423 0 0
sw s3, 12(sp) 0x01312623 0 0
sw ra, 16(sp) 0x00112823 0 0
addi s0, zero, 25 0x01900413 0 0
addi s1, zero, 0 0x00000493 0 0
addi s2, zero, 0 0x00000913 0 0
bge zero s0, done 0x02805263 1 7 (+7) setup(0)
loop:
andi s3, s1, 1 0x0014f993 2 15 (+8) resolve(-1) resolve(1)
bne s3, s1, label1 0x00999663 1 22 (+7) setup(1)
add s2, s2, s1 0x00990933 0 26 (+4) resolve(-1)
j label2 0x00c0006f 0 26
label1:
beq s0, s2, label2 0x01240463 3 37 (+11) setup(2) resolve(1)
addi s2, s2, 1 0x00190913 0 41 (+4) resolve(-1)
label2:
addi s1, s1, 1 0x00148493 2 45 (+4) resolve(1)
blt s1, s0, loop 0xfe84c2e3 1 52 (+7) setup(3)
done:
lw s0, 0(sp) 0x00012403 2 60 (+8) resolve(-1) resolve(1)
lw s1, 4(sp) 0x00412483 0 60
lw s2, 8(sp) 0x00812903 0 60
lw s3, 12(sp) 0x00c12983 0 60
lw ra, 16(sp) 0x01012083 0 60
addi sp, sp, 20 0x01410113 0 60
ret 0x00008067 0 60
SENTINEL 0xffffffff -1 -1
Here is an example of where each template should be in
modifiedInstructionsArray. Assume setup(x) includes
all the code in the Prediction setup template for a branch Id
x, resolve(-1) includes all the code in
the Prediction resolve fallthrough template, and
resolve(1) includes all the code in the Prediction
resolve target template.
demo:
addi sp, sp, -20
sw s0, 0(sp)
sw s1, 4(sp)
sw s2, 8(sp)
sw s3, 12(sp)
sw ra, 16(sp)
addi s0, zero, 25
addi s1, zero, 0
addi s2, zero, 0
[setup(0)] # setup for branch Id 0
bge zero s0, done
[resolve(-1)] # resolve fallthrough
loop:
[resolve(1)] # resolve target
andi s3, s1, 1
[setup(1)] # setup for branch Id 1
bne s3, s1, label1
[resolve(-1)] # resolve fallthrough
add s2, s2, s1
j label2
label1:
[resolve(1)] # resolve target
[setup(2)] # setup for branch Id 2
beq s0, s2, label2
[resolve(-1)] # resolve fallthrough
addi s2, s2, 1
label2:
[resolve(1)] # resolve target
addi s1, s1, 1
[setup(3)] # setup for branch Id 3
blt s1, s0, loop
[resolve(-1)] # resolve fallthrough
done:
[resolve(1)] # resolve target
lw s0, 0(sp)
lw s1, 4(sp)
lw s2, 8(sp)
lw s3, 12(sp)
lw ra, 16(sp)
addi sp, sp, 20
ret
Adjusting Relative offsets
Branch instructions and jump instructions do not use absolute
addresses to specify their target. Instead, they use relative
offsets, which indicates how far to jump from the current
instruction. The offset is a signed value, allowing branches both
forward and backward, and is stored in the immediate partitions of
the instruction formats. Using the second branch instruction in demo as
an example, in the original function the second branch
targets label1 which is 3 instructions (12 bytes)
forwards. However, looking at the template placements in the
modified function, a resolve(-1),
resolve(1), and a setup(2) template have
been inserted in between this branch and its target, totaling 15
extra instructions (60 new bytes). The immediate of the branch
instruction needs to be adjusted and the target instruction of the branch
should change before the modified function can
be run. The new branch target should be the first
instruction of the resolve(1) template because this
is now the instruction at label1. Thus, the
immediate of the branch only needs to be adjusted for the
resolve(-1) inserted code. The new branch immediate should
therefore be 12 + 16 = 28, and the branch instruction should be
modified from 0x00999663 to
0x00999e63.
Below is a visual example of how a branch immediate will increase after instrumentation.
The branch encoding will have to be modified to account for the new immediate, else the modified program will likely crash.
Decoding Instructions
The RISC-V instruction set architecture (ISA) design uses a
standard instruction format that makes decoding straighforward.
Decoding follows a two-level procedure: a 7-bit
opcode identifies the instruction format and, within
each format, a 3-bit funct3 field specifies the exact
instruction. Take a look at the core instruction formats
below.

Let’s disassemble the second branch instruction
(0x00999663) of the demo function as an
example:
0x00999663 = 0000 0000 1001 1001 1001 0110 0110 0011
opcode = 110 0011
funct3 = 001
From the opcode, we can determine that this is an
SB-type instruction. By examining both the
opcode and the funct3 field, we can
further deduce that this is a bne instruction.
Writing a Solution
The directive .include "common.s" in the provided solution file (perceptron_predictor.s) causes RARS to execute the code in the common.s file before executing any code in the solution file.
The code in common.s reads a binary file provided in the program arguments, initializes the arguments, runs unit tests, then calls perceptronPredictor.
Functions to Complete
Write all the following RISC-V functions in the file perceptron_predictor.s:
Description:
The primary function that initiates the instrumentation and execution stages.
This function must instrument the input binary, train and run the predictor,
then print the results.
Arguments:
a0: Pointer to originalInstructionsArray
a1: Pointer to modifiedInstructionsArray
a2: Pointer to instructionIndicatorsArray
a3: Pointer to numPriorInsertionsArray
Returns:
None
fill_instructionIndicatorsArray
Description:
This function is responsible for filling instructionIndicatorsArray.
Arguments:
a0: Pointer to originalInstructionsArray
a1: Pointer to instructionIndicatorsArray
Returns:
None
Description:
This function is responsible for filling numPriorInsertionsArray.
Arguments:
a0: Pointer to instructionIndicatorsArray
a1: Pointer to numPriorInsertionsArray
Returns:
None
fill_modifiedInstructionsArray
Description:
This function is responsible for filling modifiedInstructionsArray.
it copies instructions from originalInstructionsArray and adds the required
instrumentation instructions by calling insertSetupInstructions
and insertResolveInstructions
Arguments:
a0: Pointer to originalInstructionsArray
a1: Pointer to modifiedInstructionsArray
a2: Pointer to instructionIndicatorsArray
a3: Pointer to numPriorInsertionsArray
Returns:
None
Description:
Makes a prediction on whether a particular branch will be taken or not taken,
given the program state and branch Id
Arguments:
a0: Branch id
Returns:
None
Description:
Trains the perceptron corresponding to the branch id stored in activeBranch.
Arguments:
a0: Actual branch outcome (1 if taken, else -1)
Returns:
None
Helper Functions
There are also completed helper functions located at the bottom of the solution file:
Description:
Creates and loads the pre-branch setup instructions into the
modified array for a given branch id.
Arguments:
a0: Pointer to the location in modifiedInstructionsArray to store the
sequence of setup instructions
a1: Branch id
Returns:
None
Description:
Creates and loads branch fallthrough OR branch target instructions into the
modified array for a given branch id.
Arguments:
a0: Pointer to the location in modifiedInstructionsArray to store the
sequence of fallthrough OR target instructions
a1: 0 if resolving a fallthrough or 1 if resolving a branch target
Returns:
None
Description:
Takes a SB-type branch instruction and extracts the sign-extended immediate.
Arguments:
a0: an SB (branch) instruction word
Returns:
a0: a sign extended immediate
Description:
Takes an immediate value and SB-type branch instruction and sets the
immediate in the instruction.
Arguments:
a0: an SB (branch) instruction word
a1: the immediate value to set
Returns:
a0: the modified instruction with the new immediate value.
Description:
Prints the modifiedInstructionsArray, the weights for each branch, and accuracy
statistics. Should be called as the final step in the solution.
Arguments:
a0: Pointer to modifiedInstructionsArray
a1: Max branch Id
a2: Total branch instructions executed
a3: Total correct predictions
Returns:
None
Description:
Prints an array or weights.
Arguments:
a0: Pointer to an array of weights.
Returns:
None
Optional Functions
Two incomplete optional functions that are defined in perceptron_predictor.s. These are helpful for the creation of the solution, but they are not graded. If using these functions, make sure to complete their implementation.
Description:
Takes a UJ-type jump instruction (jal), and extracts the sign-extended immediate.
Arguments:
a0: a UJ (jal) instruction word
Returns:
a0: sign extended immediate
Description:
Takes an immediate value and UJ-type jal instruction and sets the immediate in the instruction.
Arguments:
a0: a UJ (jal) instruction word
a1: the immediate value to set
Returns:
a0: the modified jal instruction with the new immediate
In RISC-V assembly, every function must have a return statement. The following are examples of valid return statements: ret, jr ra, and jalr zero, 0(ra).
The perceptron_predictor.s file already includes the function labels above and each ends with a return statement.
Do not change the names of these functions, as they are called for unit testing in the common.s file.
Do not change the names or definitions of any of the functions, data structures, or variables listed above. You are free to create new helper functions as you wish.
Assumptions and Notes
- The input function provided to
perceptronPredictor.sis entirely self contained and deterministic. This means the output is identical each time it is run, and the program takes no arguments. - Every input function will have at least one branch type instruction.
- The input function provided to
perceptronPredictor.swill consist of at most 255 instructions. - The input function provided to
perceptronPredictor.swill consist of at most 32 branch instructions. - There will be no calls to other functions within the input function.
- There will be no load or store instructions (including the
lainstruction) within the input function. - Other than
ra, onlysregisters are used in the original input function. The templates includeaandtregisters, so these will exist in the modified function. The reason for only usingsregisters is that the function calls can be inserted anywhere and there is no guarantee that the original function's temporary registers would be restored after the inserted function call. - Every input function will correctly save all
sregisters that it uses to the stack immediately after its initial label. - Remember, a non-negative output is interpreted as predict taken.
Testing your Lab
For this lab, there is only one program argument required: the binary file of the input function (e.g., demo.bin). You must provide the full path of this file in the program arguments section in the Execute tab on RARS. Ensure that the path adheres to the following criteria:
- No quotation marks around the path.
- No spaces in the path or file names.
Users/JohnDoe/CMPUT-229/Lab 6/Code/Tests/nested_loop.bin. The space in the folder name Lab 6 can cause issues when trying to locate the file. It is recommended to rename it to Lab-6 or another name without spaces to avoid any problems.
The common.s file contains some unit tests to help test the solution. This testing works on a predefined input function and checks whether the output from functions in perceptron_predictor.s matches the expected output. The tests are hardcoded and do not run on the file specified in the program arguments. The results of the unit tests can be viewed in the Run I/O panel of RARS.
The Tests folder contains some input functions with
their corresponding expected outputs (correct
modifiedInstructionArray, weights arrays, and
statistics information). These functions are also in the
Code folder. Although passing these tests is
essential, it does not guarantee full marks as they are not
extensive. You can create your own corner-case tests to ensure
that your code is correct.
Creating Test Cases
To create a test case, first write a RISC-V test function in an
assembly file. Use the command:rars a dump .text Binary
<INPUT_FUNCTION.bin> <INPUT_FUNCTION.s>. The
binary file generated by this command can serve as a program
argument in RARS for perceptron_predictor.s. Use the
full file path, ensuring to specify the binary (.bin) file for
input, not the assembly (.s) file.
Running from the command line
If you wish to run your solution from a terminal, ensure to add the "smc" argument to the rars command to enable self-modifying code.
rars smc perceptron_predictor.s pa input_function.bin
Instruction Disassembly
The printResults function in
perceptron_predictor.s parses some of the the data
structures populated by your solution, including the
modifiedInstructionsArray. From this, you can inspect
the instructions in the
modifiedInstructionsArray. Instructions are represented
in hexadecimal format, so a disassembler can be used to verify that
the input function has been correctly instrumented. This is an
optional task.
This lab has an additional folder in the Code
folder called Disassembly. It contains files that
perform instruction disassembly which is the process of translating
hexadecimal instructions to their corresponding RISC-V assembly
instructions. This code is from an Open
Source RISC-V Disassembler. Please contact a TA if you run into
any issues using the code.
To utilize this disassembler, follow these steps:
-
First, compile the file
print-instructions.cusing a C compiler. For example, from the terminal, execute the command:gcc print-instructions.c -o disassemblerorclang print-instructions.c -o disassembler. - Create a file containing the hexadecimal instructions to disassemble by copying and pasting your RARS output into a text file.
-
Run the executable with the hexadecimal text file as a program argument. For example:
./disassembler RARS-instructions.txt.
See the README.md in the Disassembly
folder for more information.
Resources
Marking Guide
Assignments too short to be adequately judged for code quality will be given a zero for that portion of the evaluation.
- 20% for
perceptronPredictor - 12% for
fill_instructionIndicatorsArray - 12% for
fill_numPriorInsertionsArray - 12% for
fill_modifiedInstructionsArray - 12% for
makePrediction - 12% for
trainPredictor - 20% for code cleanliness, readability, and comments
Submission
There is a single file to be submitted for this lab (perceptron_predictor.s ) and it should contain the code for your solution.
- Do not add a
mainlabel to this file. - Do not modify the function names.
- Do not remove the CMPUT 229 Student Submission License at the top of the file containing your solution and remember include your name in the appropriate section of this text.
- Do not modify the line
.include "common.s". - Do not modify the
common.sfile. - Keep the files in the
Codefolder of the git repository. - Push your repository to GitHub before the deadline. Just committing will not upload your code. Check online to ensure your solution is submitted.