
CMPUT 229 — Computer Organization and Architecture I
Lab 3: Cache Simulator
Creator: Max Leontiev
Introduction
This lab simulates a two-way set associative cache. The input is a list of memory accesses (loads/stores with addresses) representing the memory accesses that a program performs during its runtime. The lab solution simulates the updates to the LRU bits, valid bits, and tags in the cache, and keeps track of hits and misses (logging them as they occur). Finally, the number of hits, number of misses, and hit rate is printed. The high-level goal of the lab is to gain an intuitive understanding of how caches work.
Background
Principle of Locality
Programs need to perform many memory accesses during runtime; a complex program may perform billions of memory accesses throughout the course of normal operation. The principle of locality states that, at any instant in time, programs tend to access only a small subset of the memory available to them. There are two types of locality:
- Temporal locality (locality in time): if an item is referenced, it is likely to be referenced again soon
- Spatial locality (locality in space): if an item is referenced, items whose addresses are close by are likely to be referenced soon
Memory Hierarchy
The memory hierarchy takes advantage of the principle of locality to provide fast access to memory (on average) while minimizing the cost of the hardware. The textbook provides the following definition of memory hierarchy:
The memory hierarchy is a structure that uses multiple levels of memories; as the distance from the processor increases, the size of the memories and the access time both increase while the cost per bit decreases.
Patterson and Hennessy, Computer Organization and Design RISC-V Edition (2nd ed.)
Cache Memory
High-speed memory that is small in size (usually on the order of kilobytes or megabytes) and high in the memory hierarchy (close to the processor) is called cache memory. Cache memory sits between the processor and main memory (DRAM) in the memory hierarchy, storing a subset of main memory data that the processor is likely to need soon, as well as data that has recently been written (depending on the scheme being used).
Modern processors have multiple levels of caches to maximize performance. For example, the AMD Ryzen 7 5700X has a 512 KB L1 (level 1) cache, 4 MB L2 (level 2) cache, and 32 MB L3 (level 3) cache. Additionally, most processors have separate caches for instructions (I cache) and data (D cache).
The unit of transfer between the different levels of the memory hierarchy is called a block or line. A block consists of multiple (eg. 4) words. The number of words in a block is the block size.
A cache hit occurs when the processor finds the requested data in the upper level of the memory hierachy. Accordingly, a cache miss occurs when the processor does not find the requested data in the upper level of the memory hierarchy. When a cache miss occurs, the processor must fetch the requested data from a lower level in the hierarchy.
The hit rate is the fraction of memory accesses that are satisfied by the upper level. To put this into perspective, a level 1 cache hit rate of around 95% is realistic, which would mean that 95 out of every 100 requests (on average) are satisfied by the level 1 cache and requests to a lower level in the hierarchy are only required for 5 in every 100 requests (on average). The hit rate is often used as a measure of the performance of the memory hierarchy. The miss rate (\(1 - \text{hit rate}\)) is the fraction of memory accesses that are not satisfied by the upper level. For example, if the hit rate is 95%, then the miss rate is 5%.
Cache Organization
Associativity
When the processor handles a memory request, the processor needs to determine if a block containing the requested data is in the cache or if the block must be fetched from a lower level in the hierarchy. How this is done depends on the mapping between memory addresses and cache blocks. The associativity of a cache determines the number of locations in the cache where a given block of memory can be stored:
- Direct mapped: Each memory address maps to exactly one block in the cache. Direct-mapped caches use the following formula to find a block: \[(\text{block address})\ \text{modulo}\ (\text{number of blocks in the cache})\]
- \(n\)-way set associative: Each memory address maps to a set of blocks in the cache, and the data at that address can be in any of the blocks in the set. Each set contains \(n\) blocks, also known as ways.
- Fully associative: Each memory address maps to any block in the cache. This scheme is only practical for very small caches. A fully associative cache can be viewed as a special case of an \(n\)-way set associative cache where there is one set that contains \(n\) blocks.
This lab simulates a two-way set associative cache, meaning that the cache consists of many sets which each contain two blocks.
Finding an address in a set associative cache: tag, index, offset
When looking for an address in a set associative cache, the address of the access is split up into three parts: the tag, index, and offset.
-
The index identifies the set that the requested address maps to. For
example, if the index is
1100, the set with index1100is checked to see if it has the requested block. The set with index1100is the thirteenth set in the cache (since \({1100}_{2} = 12_{10}\) and the sets are zero-indexed). - The tag of the requested address is compared with the tags in the blocks in the set to determine if there is valid data in the cache for the requested address. Each block in the cache has a valid bit which is 1 if the block contains valid data, and 0 otherwise. A cache hit occurs if the valid bit for a block in the set is 1 and the tag of the block matches the tag of the access.
- The offset identifies where the requested word is located within the block by acting as a byte offset from the beginning of the block. For example, if the word size is four bytes, then an offset of zero would correspond to the first word in the block, an offset of four would correspond to the second word in the block, and so on.
Given the size of the cache \(C\) (in bytes) and block size \(B\) (number of words per block), the number of tag, index, and offset bits can be calculated using the following formulas:
- Let \(B\) be the block size (number of words per block). The number of bytes per block and the number of offset bits are: \[\text{# bytes per block} = B \times \text{# bytes per word}\] \[\text{# offset bits} = \log_2(\text{# bytes per block})\]
- Let \(n\) be the associativity of the cache (for example, \(n = 2\) for a two-way set associative cache). The number of bytes per set is: \[\text{# bytes per set} = n \times \text{# bytes per block}\]
- Let \(C\) be the size of the cache in bytes. The number of sets, the number of index bits, and the number of tag bits are: \[\text{# sets} = \frac{C}{\text{# bytes per set}}\] \[\text{# index bits} = \log_2(\text{# sets})\] \[\text{# tag bits} = \text{# address bits} - \text{# index bits} - \text{# offset bits}\]
These calculations are not part of the lab solution. However, it is still important to understand the calculations in order to create test cases.
For an example of these calculations, see the animation below.
In this course, \(1\ \text{KB} = 1024\ \text{bytes}\)
The following animation expands on the example in the previous animation by showing how the address of a request is split into its tag, index, and offset.
Replacement Policy
An additional consideration when designing a cache is the replacement policy. Data in the cache must occasionally be replaced with new data that is fetched because the cache has a much smaller capacity than main memory. A cache that implements the least-recently used (LRU) replacement policy replaces blocks that were used (read/written to) least recently. According to the principle of temporal locality, the most recently used blocks are likely to be used again in the near future, which is why the LRU policy replaces the least recently used block.
In the case of an \(n\)-way set associative cache, an LRU replacement policy requires a mechanism to keep track of which of the \(n\) ways in a set was used least recently. When a new block is fetched into that set, the least recently used block in that set is replaced. In a two-way set associative cache, the LRU policy is implemented with a single LRU bit for each set that indicates which of the blocks in the set (block 0 or block 1) was used least recently.
Write Strategy
The policy for dealing with writes is called the write strategy of the cache. There are two common write strategies on a write hit (the block being written to is in the cache):
- Write-back: This policy requires each block to have a dirty bit. The dirty bit for a block is 1 if the block is dirty, meaning that it has been written to in the cache but has not been written back to memory yet (the data for this block in memory is stale). In the case of a write hit, always write to the cache. Set the dirty bit to 1 to indicate that the block is dirty. When that block is replaced, write the block back to the memory and reset the dirty bit back to 0.
- Write through: In the case of a write hit, write to the cache and the memory at the same time. There is no need for a dirty bit since the data in memory is always consistent with the data in the cache.
There are two corresponding strategies on a write miss (the block being written to is not in the cache):
-
Write-allocate with write-back: This policy
requires each block to have a dirty bit. The dirty
bit for a block is 1 if the block is dirty, meaning
that it has been written to in the cache but has not been written
back to memory yet (the data for this block in memory is
stale). In the case of a write miss, fetch the
block being written to from memory into the cache and write on it.
Set the dirty bit to 1 to indicate that the block is dirty. When
that block is replaced, write the block back to the memory and reset
the dirty bit back to 0.
Fetching the block before writing on it ensures that any unmodified words in the block are preserved in memory after writing back. This is necessary because the whole block must be transferred when writing back to memory.
- Write around with write through: In the case of a write miss, write only to memory without bringing the block into the cache.
Cache Simulator
This lab consists of implementing four functions that simulate a two-way set associative cache given a list of requests (loads/stores with addresses).
The cache uses the LRU replacement policy, meaning that there is an LRU bit for each set indicating which block in that set was used least recently. The cache uses the write-back strategy for write hits, and the write-allocate with write-back strategy for write misses (see the background section).
The lab consists of implementing the following functions:
simulateCachesimulateRequestsimulateHitsimulateMiss
These functions are described in detail below. It is recommended to
implement the functions in the order that they are listed
(simulateCache,
simulateRequest, simulateHit, and finally
simulateMiss). simulateMiss is the most
complicated part of the lab — a good strategy is to implement it
last.
When implementing these functions, the Register Usage section
must be filled out in their header comments to
describe the usage of the t and s registers
in the function. For some examples of how to properly document
register usage, see the functions in common.s.
Do not modify common.s.
The lab solution must use the requests,
tags, and meta_bytes arrays provided by
common.s. These arrays are described in the
data structures section.
This lab provides the logHit and
logMiss helper functions for printing the required
output. The lab solution must call them to print the
required output. Other provided helper functions compute the tag,
index, and offset of an address (see the
helper functions section).
# -----------------------------------------------------------------------------
# simulateCache:
#
# Simulates a two-way set associative cache.
#
# simulateCache must loop over the requests array, calling simulateRequest
# for each request and counting the number of hits and misses that occur.
# simulateCache must return the total number of hits and the total number of
# misses.
#
# Args:
# a0: N, the number of requests to memory in the input
#
# Returns:
# a0: the total number of hits that occurred
# a1: the total number of misses that occurred
#
# Register usage:
# insert your register usage for this function here
# -----------------------------------------------------------------------------# -----------------------------------------------------------------------------
# simulateRequest:
#
# Simulates a single request, given a pointer to a request in the REQUESTS
# array. First, simulateRequest must call getTag, getIndex, and getOffset to
# get the tag, index, and offset of the requested address.
#
# Then, simulateRequest must determine if the request is a hit or a miss by
# comparing the tag of the requested address with the tags of the valid blocks
# in the set at the index of the requested address. If block 0 is valid (the
# valid0 bit is 1) and the tag of block 0 matches the tag of the requested
# address, then there is a hit on block 0. Similarly, if block 1 is valid
# (the valid1 bit is 1) and the tag of block 1 matches the tag of the
# requested address, then there is a hit on block 1. Otherwise, the request
# results in a miss.
#
# If the request results in a hit, simulateRequest must call simulateHit and
# return 1. If the request results in a miss, simulateRequest must call
# simulateMiss and return 0.
#
# Args:
# a0: pointer to a request in the requests array
#
# Returns:
# a0: 1 if the request resulted in a hit, 0 if the request resulted in a miss
#
# Register usage:
# insert your register usage for this function here
# -----------------------------------------------------------------------------# -----------------------------------------------------------------------------
# simulateHit:
#
# Given the block that the hit occurred on (block 0 or block 1),
# simulateHit must set the LRU bit to the opposite block (if the hit was on
# block 0, the LRU bit should be set to 1; if the hit was on block 1, then the
# LRU bit should be set to 0).
#
# If the request was a load, the dirty bit of the requested block must be left
# unchanged. If the request was a store, then simulateHit must set the dirty
# bit of the requested block to 1.
#
# simulateHit must call logHit to print information about the hit.
#
# Args:
# a0: 0 if the request is a load, 1 if the request is a store
# a1: tag of the requested address
# a2: index of the requested address
# a3: offset of the requested address
# a4: pointer to meta_bytes[index]
# a5: 0 if the hit is on block 0, 1 if the hit is on block 1
#
# Register usage:
# insert your register usage for this function here
# -----------------------------------------------------------------------------# -----------------------------------------------------------------------------
# simulateMiss:
#
# simulateMiss must determine which block to replace by checking the LRU bit
# of the set (if the LRU bit is 0, replace block 0; if the LRU bit is 1,
# replace block 1). Then, simulateMiss must check the valid bit and dirty bit
# of the replaced block to determine if a write-back should occur (if the
# valid bit is 1 and the dirty bit is 1, then write-back; otherwise, don't
# write-back).
#
# simulateMiss must set the dirty bit of the replaced block to
# 0 if the request is a load or 1 if the request is a store.
#
# simulateMiss must call logMiss to print information about the miss and
# whether or not a write-back occurred.
#
# simulateMiss must replace the tag of the replaced block with the tag of the
# request, and set the valid bit of the replaced block to 1. Lastly,
# simulateMiss must update the LRU bit of the set to the non-replaced block
# (if block 0 was replaced, then the LRU bit should be set to 1; if block 1
# was replaced, then the LRU bit should be set to 0).
#
# Args:
# a0: 0 if the request is a load, 1 if the request is a store
# a1: tag of the requested address
# a2: index of the requested address
# a3: offset of the requested address
# a4: pointer to tags[index]
# a5: pointer to meta_bytes[index]
#
# Register usage:
# insert your register usage for this function here
# -----------------------------------------------------------------------------Helper Functions
The following helper functions are provided:
-
logHitfor printing information about a cache hit -
logMissfor printing information about a cache miss getTagfor getting the tag of an addressgetIndexfor getting the index of an addressgetOffsetfor getting the offset of an address
A correct lab solution must call
logHit and logMiss to print the required
output.
Each helper function is described in detail below.
The helper functions are implemented in common.s.
Do not modify common.s.
# -----------------------------------------------------------------------------
# logHit (helper):
#
# Prints a line of information about a request that resulted in a cache hit.
#
# The format of the logged line is:
# Hit, valid block a3 with tag a0 (offset: a2) found in set a1.
#
# Args:
# a0: the tag of the request
# a1: the index of the request
# a2: the offset of the request
# a3: 0 if the hit is on block 0, 1 if the hit is on block 1
#
# Register Usage:
# s0-3: store a0-3
# -----------------------------------------------------------------------------# -----------------------------------------------------------------------------
# logMiss (helper):
#
# Prints a line of information about a request that resulted in a miss.
#
# If a write-back occurred, the format of the logged line is:
# Miss, no valid block with tag a0 (offset: a2) found in set a1.
# Replacing block a3 (had tag a4). Writing back block a3.
# If a write-back did not occur, the format of the logged line is:
# Miss, no valid block with tag a0 (offset: a2) found in set a1.
# Replacing block a3 (had tag a4).
#
# Args:
# a0: the tag of the request
# a1: the index of the request
# a2: the offset of the request
# a3: 0 if block 0 is being replaced, 1 if block 1 is being replaced
# a4: the tag of the replaced block
# a5: 0 if the request did not result in a write-back, 1 if the request
# resulted in a write-back
#
# Register Usage:
# s0-5: store a0-5
# -----------------------------------------------------------------------------# -----------------------------------------------------------------------------
# getTag (helper):
#
# Get the tag of an address.
#
# Args:
# a0: address word
#
# Returns:
# a0: a word containing the tag of the address. The least significant
# NUM_TAG_BITS bits of this word are the value of the tag,
# and the remaining bits in the word are 0.
#
# Register Usage:
# t0: NUM_TAG_BITS value
# t1: constant 32
# t2: value of (32 - NUM_TAG_BITS)
# -----------------------------------------------------------------------------# -----------------------------------------------------------------------------
# getIndex (helper):
#
# Get the index of an address.
#
# Args:
# a0: address word
#
# Returns:
# a0: a word containing the index of the address. The least significant
# NUM_INDEX_BITS bits of this word are the value of the index,
# and the remaining bits in the word are 0.
#
# Register Usage:
# t0: NUM_TAG_BITS value
# t1: NUM_OFFSET_BITS value
# t2: value of (32 - NUM_INDEX_BITS)
# -----------------------------------------------------------------------------# -----------------------------------------------------------------------------
# getOffset (helper):
#
# Get the offset of an address.
#
# Args:
# a0: address word
#
# Returns:
# a0: a word containing the offset of the address. The least significant
# NUM_OFFSET_BITS bits of this word are the value of the offset,
# and the remaining bits in the word are 0.
#
# Register Usage:
# t0: NUM_OFFSET_BITS value
# t1: constant 32
# t2: value of (32 - NUM_OFFSET_BITS)
# -----------------------------------------------------------------------------Data Structures
The requests array contains information about the
requests that were passed as input. common.s parses
the input file and initializes the requests array
before calling the simulateCache function. The lab
solution should never write to this array.
Use the REQUESTS global variable to access the
requests array. This global variable points to the
base address of the requests array. The RISC-V
instruction la t0, REQUESTS loads the address of the
first element of the requests array into the
temporary register t0.
Each request corresponds to an element of the
requests array. Each request is represented by two
32-bit words:
-
0if the request is a load,1if the request is a store - The requested address
Each request can be thought of as a
struct:
struct request {
int isStore; // 0 if request is a load, 1 if request is a store
int address; // requested address
};
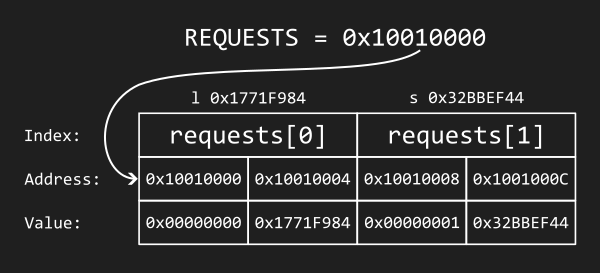
For instance, the load_and_store.txt test case
consists of two requests: l 0x1771F984 and then
s 0x32BBEF44. The requests array for
this test case is shown below as an example. Asssume that the
REQUESTS global variable is equal to
0x10010000, meaning that the
requests array begins at address
0x10010000.
The tags array contains the tags for the blocks in
each set. common.s parses the input file and
initializes all of the tags to 0 before calling the
simulateCache function.
The lab solution must update the tags in the
tags array when simulating a cache miss.
For more details, read the
Cache Simulator section.
To access the tags array in the lab solution, the
TAGS global variable is provided. This global
variable is a pointer to the base address of the
tags array. The RISC-V instruction
la t0, TAGS loads the address of the first element of
the tags array into the temporary register
t0.
Each element of the tags array consists of two 32-bit
words. tags[i] consists of:
-
The tag for block 0 of the set with index
i. The least significantNUM_TAG_BITSbits of this word are the tag for block 0. The remaining bits are always 0 (assuming that they are not accidentally modified in the lab solution). -
The tag for block 1 of the set with index
i. The least significantNUM_TAG_BITSbits of this word are the tag for block 1. The remaining bits are always 0 (assuming that they are not accidentally modified in the lab solution).
Each element of the tags array can be thought of as a
struct:
struct tagsOfSet {
int tag0; // tag for block 0
int tag1; // tag for block 1
};
The meta_bytes array is used to store the LRU bits
for each set, and the valid and dirty bits for each block.
common.s parses the input file and initializes all of
the meta bytes to 0 before calling the
simulateCache function.
The lab solution must update the meta_bytes array
when simulating requests.
For more details, read the
Cache Simulator section.
To access the meta_bytes array in the lab solution,
the META_BYTES global variable is provided. This
global variable is a pointer to base address of the
meta_bytes array. The RISC-V instruction
la t0, META_BYTES loads the address of the first
element of the meta_bytes array into the temporary
register t0.
To load an element of the meta_bytes array into a
register, use the lbu (load byte unsigned)
instruction. For example, assuming t0 contains the
address of the first element of the meta_bytes array,
lbu t1, 0(t0) loads the first element of the
meta_bytes array into the register t1.
Each element of the meta_bytes array is a
meta byte, where:
- Bits 7-5 are not used for this lab. These bits are always 0 (assuming that they are not accidentally modified in the lab solution). The lab solution should only ever modify bits 4-0.
-
Bit 4 is the LRU bit. This bit
should be set to 0 if block 0 has been used (read/written to)
least recently, or 1 if block 1 has been used (read/written to)
least recently. In this lab, this is referred to as the
lrubit. -
Bit 3 is the
valid bit for block 0. This bit should be set
to 1 if block 0 has valid data. Otherwise, this bit should be
set to 0. In this lab, this is referred to as the
valid0bit. -
Bit 2 is the
dirty bit for block 0. This bit should be set
to 1 if block 0 is dirty, meaning that it has been written to
and it has not been written back yet. Otherwise, this bit should
be set to 0. In this lab, this is referred to as the
dirty0bit. -
Bit 1 is the
valid bit for block 1. This bit should be set
to 1 if block 1 has valid data. Otherwise, this bit should be
set to 0. In this lab, this is referred to as the
valid1bit. -
Bit 0 is the
dirty bit for block 1. This bit should be set
to 1 if block 1 is dirty, meaning that it has been written to
and it has not been written back yet. Otherwise, this bit should
be set to 0. In this lab, this is referred to as the
dirty1bit.
For example, the byte at meta_bytes[i]
consists of the following:
- Bits 7-5 are not used for this lab.
-
Bit 4 is the
lrubit for the set with indexi, which is 1 if block 1 in setiwas used less recently than block 0 in seti. -
Bit 3 is the
valid0bit for the set with indexi, which is 1 if block 0 in setiis valid. -
Bit 2 is the
dirty0bit for the set with indexi, which is 1 if block 0 in setiis dirty. -
Bit 1 is the
valid1bit for the set with indexi, which is 1 if block 1 in setiis valid. -
Bit 0 is the
dirty1bit for the set with indexi, which is 1 if block 1 in setiis dirty.
Below is an illustration of a meta byte that has been initialized
to 0. Every meta byte in the meta_bytes array looks
like this before the lab solution is called.
The meta byte below is 0000 0000 in binary, or
0x00 in hexadecimal.

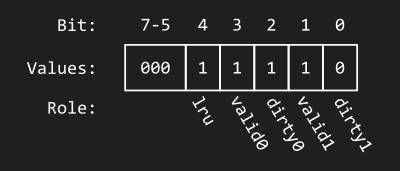
Below is an illustration of a meta byte after some requests have
been simulated. For the sake of the example, suppose that this is
meta_bytes[i].
-
Bit 4 (the
lrubit for the set with indexi) is 1, indicating that block 1 was used less recently than block 0 in seti. -
Bit 3 (the
valid0bit for the set with indexi) is 1, indicating that block 0 in setiis valid. -
Bit 2 (the
dirty0bit for the set with indexi) is 1, indicating that block 0 in setiis dirty. -
Bit 1 (the
valid1bit for the set with indexi) is 1, indicating that block 1 in setiis valid. -
Bit 0 (the
dirty1bit for the set with indexi) is 0, indicating that block 1 in setiis not dirty.
The meta byte below is 0001 1110 in binary, or
0x1E in hexadecimal.
In this lab, each set has an LRU bit, a tag for each block, a valid bit for each block, and a dirty bit for each block. In an actual cache, there would also be data for each block. For example, if the block size was four words, then there would be four words of data for block 0 and four words of data for block 1 in each set. However, data is ignored in this lab for simplicity, so this lab's representation of a set does not include it.
Testing
A small number of tests are provided in the
Tests directory of the lab repository. The provided tests
are not extensive:
you should create your own tests to ensure that your solution is
correct.
The expected output for the test files is given in the
*.out files. The format of the test input
(*.txt) files is as follows:
[N (# of requests)] [S (# of sets)]
[# of tag bits] [# of index bits] [# of offset bits]
[request 1]
[request 2]
⋮
[request N]The number of requests (loads and stores) \(N\) is an integer between 1 and 500 inclusive: \(1 \leq N \leq 500\). Make sure that this is also true for any custom test cases that you write.
The number of sets \(S\) in the cache is a power of two between 2 and 512 inclusive. This also means that \(1 \leq \text{# index bits} \leq 9\), since \(\text{# index bits} = \log_2(S)\). Make sure that \[1 \leq \text{# index bits} \leq 9 \quad \text{and} \quad \text{# index bits} = \log_2(S)\] is true for any custom test cases that you write.
The number of tag, index, and offset bits must be non-zero: \[\text{# tag bits}, \text{# index bits}, \text{# offset bits} \geq 1\] Make sure that this is also true for any custom test cases that you write.
This lab only simulates 32-bit machines, thus the number of address
bits will always be 32. Therefore, the following equation is true for
all test cases:
\[\text{# tag bits} + \text{# index bits} + \text{# offset bits} = 32\]
Make sure that the above equation is true for any custom test cases that you write, since
common.s uses the assumption that
\(\text{# tag bits} + \text{# index bits} + \text{# offset bits} =
32\).
Each request consists of either an l (load) or
s (store) character, followed by a space, followed by a
32-bit address written in
uppercase hexadecimal beginning with 0x.
For example, Tests/load_and_store.txt looks like this:
2 16
24 4 4
l 0x1771F984
s 0x32BBEF44
To run a test, provide the test file as a program argument to RARS.
This can be done in the terminal, or in the RARS graphical interface.
For example, the following command runs the test in
Tests/load_and_store.txt from the terminal:
rars cacheSimulator.s nc pa Tests/load_and_store.txt
The nc flag is required to prevent RARS from printing the
copyright notice, which interferes with the textual output. The
pa flag is required to pass program arguments (since we
are passing the test case file
Tests/load_and_store.txt as an argument).
To run the same test using the RARS graphical interface, first enable program arguments:
Then, enter the path to the test case in the field at the top of the Text Segment tab before assembling and running the program:

Below is an animation which visualizes the state of the cache during
the
load_and_store test case. The animation may be helpful
for debugging.
CheckMyLab
This lab is supported in CheckMyLab. To get started, navigate to the Cache Simulator lab in CheckMyLab found in the dashboard. From there, students can upload test cases in the My test cases table.
The test case format is described in the Testing section. See also the Assumptions and Notes section below.
Assumptions and Notes
-
All tags are initialized to 0 before
simulateCacheis called -
All LRU bits, valid bits, and dirty bits are initialized to 0 before
simulateCacheis called - The number of requests (loads and stores) \(N\) is an integer between 1 and 500 inclusive: \(1 \leq N \leq 500\)
- The number of sets \(S\) in the cache is a power of two between 2 and 512 inclusive. This also means that \(1 \leq \text{# index bits} \leq 9\), since \(\text{# index bits} = \log_2(S)\).
- \(\text{# tag bits}, \text{# index bits}, \text{# offset bits} \geq 1\)
- \(\text{# tag bits} + \text{# index bits} + \text{# offset bits} = 32\)
-
In test cases, the request addresses must be written in
uppercase hexadecimal. For example,
common.swould fail to parse the linel 0x36abcdefbecause the address uses lowercase letters. Only uppercase letters can be used in the address:l 0x36ABCDEFis valid. -
Do not modify the
REQUESTS,TAGS,META_BYTES,NUM_TAG_BITS,NUM_INDEX_BITS, orNUM_OFFSET_BITSglobal variables -
Do not use the
NUM_TAG_BITS,NUM_INDEX_BITS, orNUM_OFFSET_BITSglobal variables directly in the lab solution. Instead, to get the tag, index, and offset of an address, call the corresponding helper function (getTag,getIndex, andgetOffsetrespectively).
Resources
Marking Guide
Assignments too short to be adequately judged for code quality will be given a zero for that portion of the evaluation.
- 10% for correct overall output (including hit, miss, and hit rate logging)
- 10% for correctly implementing
simulateCache - 10% for correctly implementing
simulateRequest - 20% for correctly implementing
simulateHit - 30% for correctly implementing
simulateMiss - 20% for code cleanliness, readability, and comments
Submission
There is a single file to be submitted for this lab.
cacheSimulator.s should contain the code for all
four functions.
-
Do not add a
mainlabel to this file -
Do not modify the line
.include "common.s" -
Do not make any modifications to
common.s -
Keep the file
cacheSimulator.sin theCodefolder of the git repository