CMPUT 229 - Computer Organization and Architecture I
Lab 3: Hash Tables
Clarifications
- In the files playground.s and playground_col.s, line 79 should be
lw s0, 4(sp). - Within part 3, you do not need to implement the case where two identical strings are inserted. For example, we will not insert "CMPUT 229" twice.
- All strings will only contain ASCII characters, which range from values between 0-127. This means every character will fit in 7 bits. We will not be using any other encoding schemes, like Unicode.
- Every string will contain at least one character. For example, "a" is a valid string, but "" is not a valid string.
Introduction
A key/value store is a common data structure used in many programming languages. You may have encountered them as dictionaries in Python, objects in JavaScript, and hash maps in Java.
A hash table is a kind of key/value store; a value in a key/value store is retrieved and saved using a key. For example, if we use a hash map to represent the number of students in a course, the key CMPUT 229 would return a number such as 154. This will be our running example for the instructions.
Background
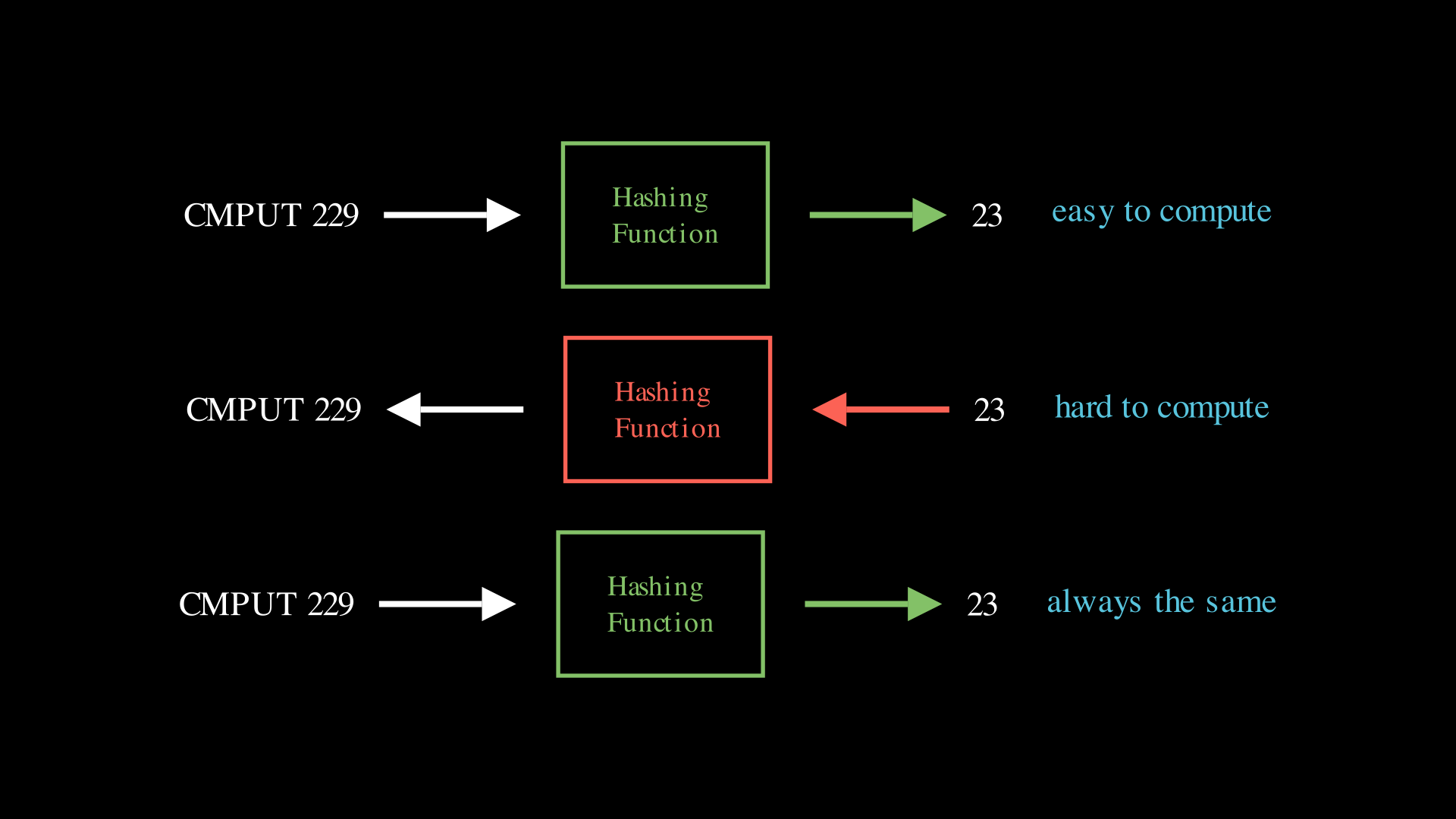 What is a hash?
A hash, or hashing algorithm, is a one-way function that returns a code of a predictable length. Every string is mapped to the same hash for that given algorithm. For example, using the algorithm in Part 1a, when the string "CMPUT 229" is inputted into the function, it will always return 23. A small change in the input could result in a completely different output. One-way means that it is easy to generate a hash from an input, but very hard to go the other way. This property makes hashing suitable for encryption and cryptography. Read more.
What is a hash?
A hash, or hashing algorithm, is a one-way function that returns a code of a predictable length. Every string is mapped to the same hash for that given algorithm. For example, using the algorithm in Part 1a, when the string "CMPUT 229" is inputted into the function, it will always return 23. A small change in the input could result in a completely different output. One-way means that it is easy to generate a hash from an input, but very hard to go the other way. This property makes hashing suitable for encryption and cryptography. Read more.
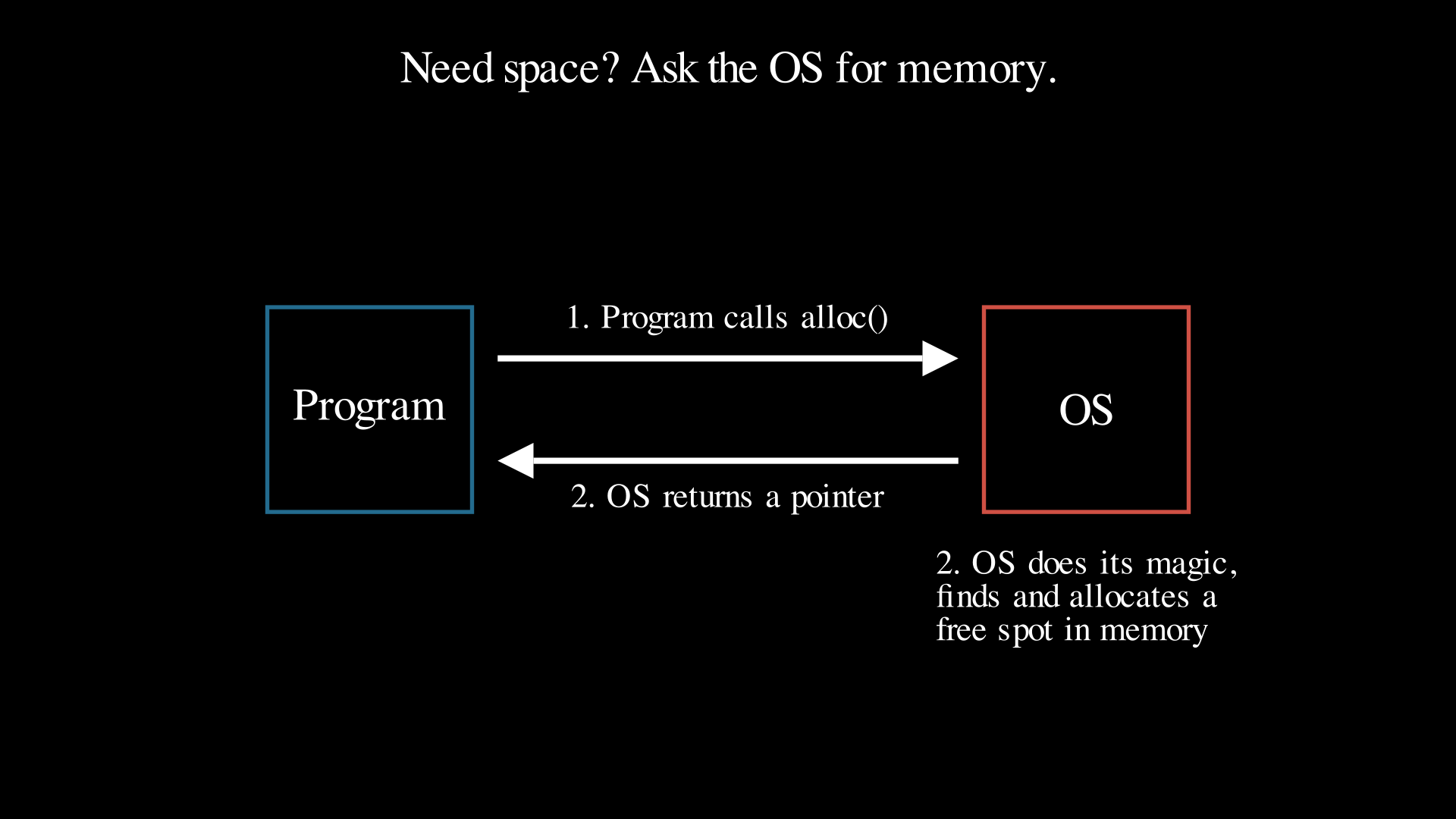 What does allocate/dynamic memory allocation mean?
Arrays work great if you know exactly how large the items you’re storing are and you know how many items you’re storing, but what if you don’t know this? For example, by the end of this lab, you could be storing hundreds or thousands of entries in a table. This is where dynamic memory allocation comes in. It allows you to allocate new memory space while your program runs. This means that the amount of memory required does not need to be known at compile time. In C, this is done with functions such as
What does allocate/dynamic memory allocation mean?
Arrays work great if you know exactly how large the items you’re storing are and you know how many items you’re storing, but what if you don’t know this? For example, by the end of this lab, you could be storing hundreds or thousands of entries in a table. This is where dynamic memory allocation comes in. It allows you to allocate new memory space while your program runs. This means that the amount of memory required does not need to be known at compile time. In C, this is done with functions such as calloc() or malloc(). These functions return memory addresses (aka. pointers) where you can store data. Read more.
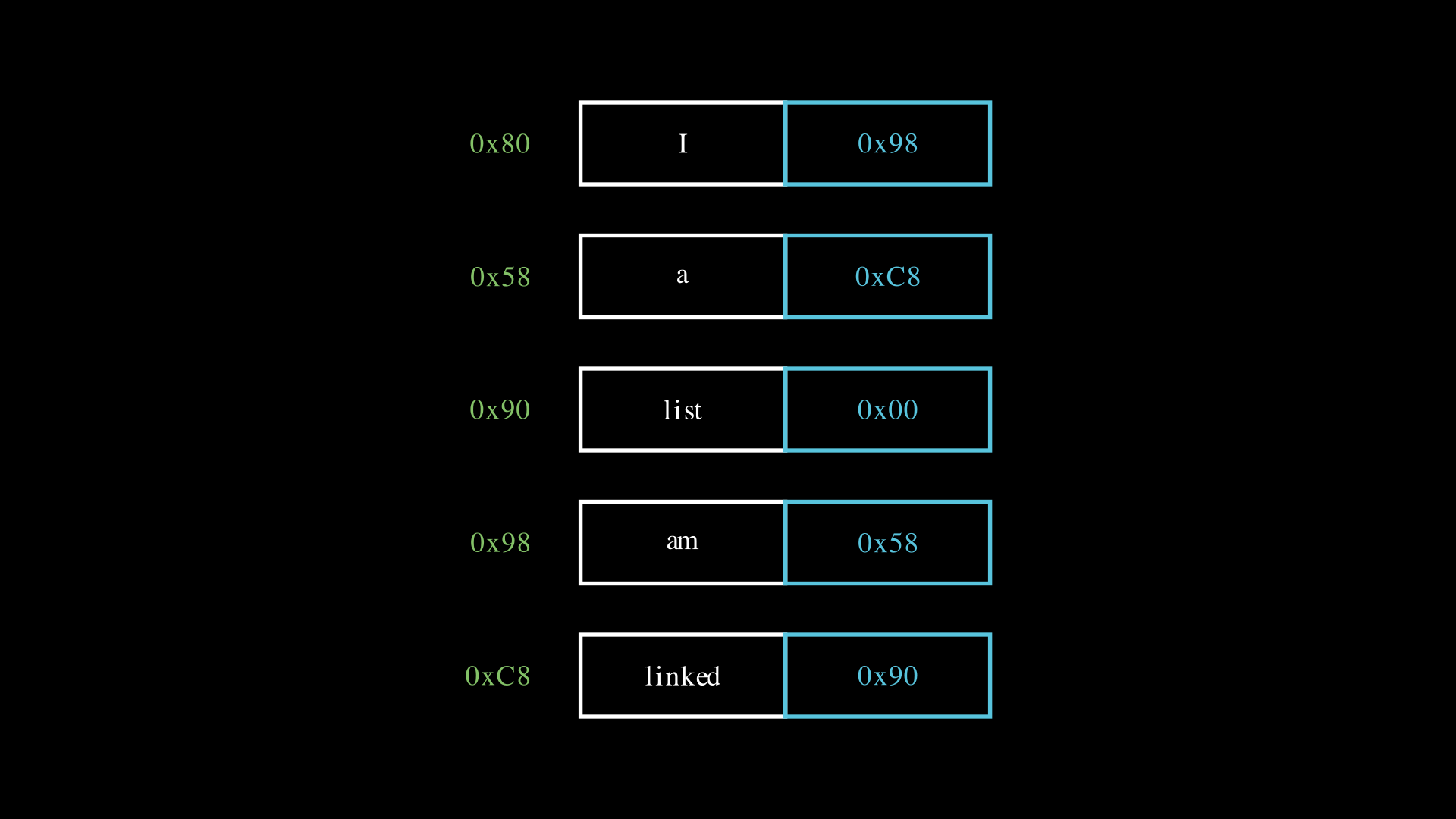
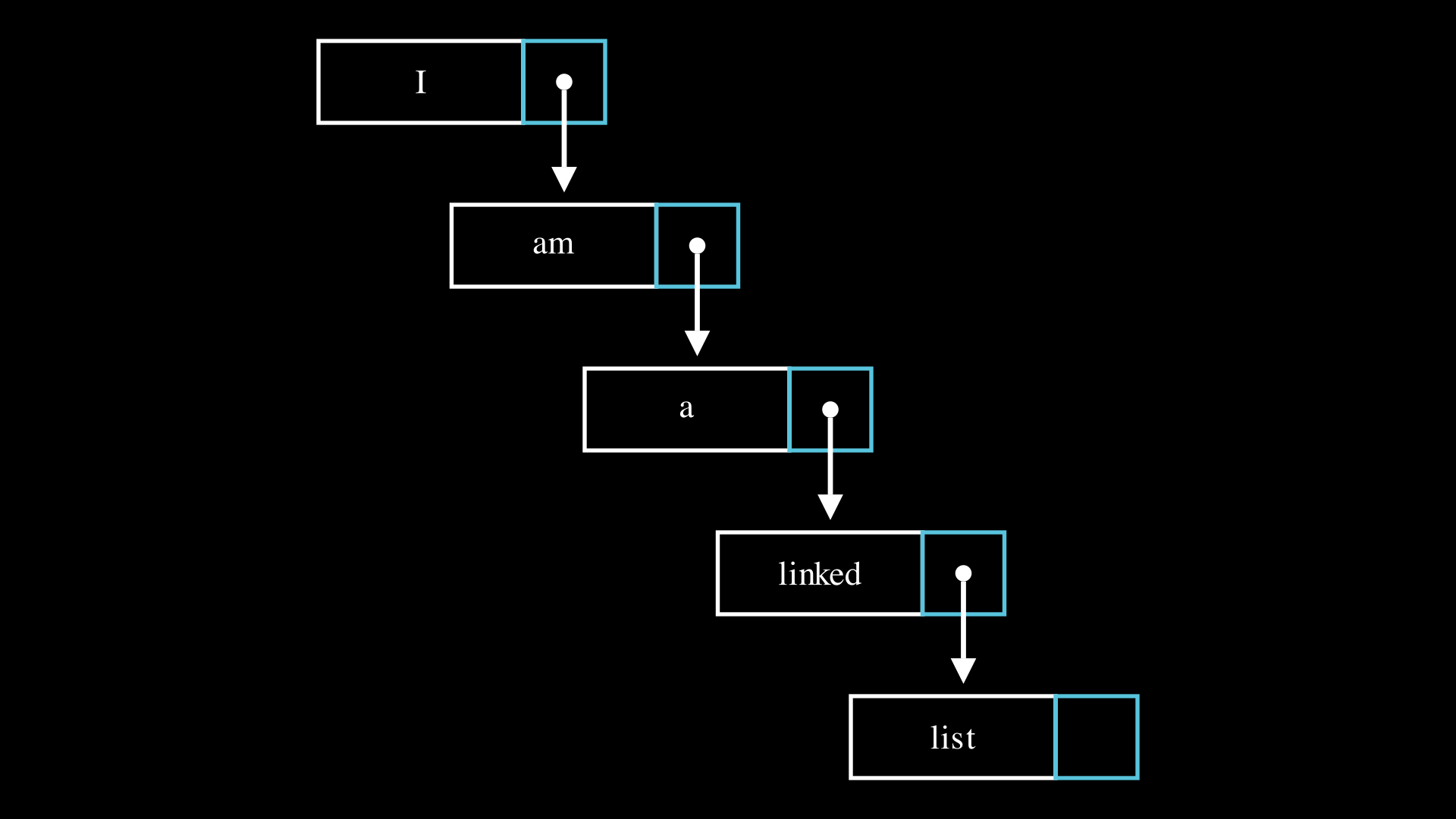 What is a linked list?
A linked list is a sequential data structure, similar to arrays. Rather than being placed right next to each other, elements of a linked lists can be anywhere in memory. Each element has a pointer to the next element in the list. Linked lists are more flexible than arrays as they allocate more memory as needed as the list grows. Later in this course, you will learn that linked list are inefficient for large-scale storage. Not only because of the additional pointer associated with each element, but also because they may hurt spatial and temporal locality which are needed for efficient cache memory utilization. Read more.
What is a linked list?
A linked list is a sequential data structure, similar to arrays. Rather than being placed right next to each other, elements of a linked lists can be anywhere in memory. Each element has a pointer to the next element in the list. Linked lists are more flexible than arrays as they allocate more memory as needed as the list grows. Later in this course, you will learn that linked list are inefficient for large-scale storage. Not only because of the additional pointer associated with each element, but also because they may hurt spatial and temporal locality which are needed for efficient cache memory utilization. Read more.
 Why is hashing used to calculate the index in this lab?
Hashes are used to determine the location of the key/value pairs. A good hashing function is one that maps keys to storage location in a way that minimizes the number of collisions --- a collision happens with two keys map to the same table entry --- more on this in Part 3. Finding a value in a hash table is much more efficient than finding a value in a sorted list or in an array, where some kind of search would be required. Calculating a hash to determine a location can be done in constant time.
Why is hashing used to calculate the index in this lab?
Hashes are used to determine the location of the key/value pairs. A good hashing function is one that maps keys to storage location in a way that minimizes the number of collisions --- a collision happens with two keys map to the same table entry --- more on this in Part 3. Finding a value in a hash table is much more efficient than finding a value in a sorted list or in an array, where some kind of search would be required. Calculating a hash to determine a location can be done in constant time.
Where is hashing used today?
Hashing is everywhere! They are a very important part of encryption, one common place they are used are on the web. Every time you see https or the lock icon in the browser, hashing is used to make your internet connection secure. Some common hashing algorithms used today are SHA-256 and MD5.
Creating a Hash Table in RISC-V
The goal of this lab is to implement a basic hash table in RISC-V with three operations: insert, search, and delete.
The first step to store data in a hash table is to calculate the hash of a key. This hash value is then used to calculate the index of the position of an array where the key/value pair will be stored. For example, using the hashing algorithm defined in Part 1a, CMPUT 229 has a hash of 23, which is used as the index of the entry.
This lab is split into 3 parts:
- Part 1 implements a hashing algorithm and a function to check the equality of two strings.
- Part 2 implements the three operations of the hash table.
- Part 3 adds the support necessary to handle collisions.
Part 1a: Implement the Hashing Algorithm
This lab uses a modified version of a simple hashing algorithm called djb2. The original algorithm was created by Dan Bernstein. This algorithm requires a seed, which is a number used to initialize a pseudorandom function. In this lab and in the original djb2 specification, 5381 is used as the seed. Please ensure you use the same seed in your implementation in order to be marked correctly.
Algorithm
hash <- seed for every character char in string do hash <- ((hash * 33) + char) % 22900 end for hash <- hash % 64 return hash
For each string, start the hash with the value of 5381. Then, loop through every character in the string and perform the following operations:
- multiply the existing hash by 33
- add the current character value to the hash
- modulo (remainder) the hash by 22900
[ex. 5381 * 33 = 177573]
[ex. C has the value 67, so 177573 + 67 = 177640]
[ex. 177640 mod 22900 = 17340]
In this example, when performing the set of operations for the next letter U, the existing hash for would be 17340 rather than 5381. Repeat these operations for each character until you reach the null character 00. Then, modulo (remainder) the hash by 64 and return this value.
[ex. CMPUT 229 will result in a value of 16599. Once you complete the final step (modulo by 64), the final value will be 23.]
Your task: Write a function hash that takes in the address of a string as the argument a0 and returns the hash in a0.
Part 1b: Implement String Equals Function
Recall how strings work: strings are a string of characters that terminate with the null character \0 or 00 in HEX. When you are given a string as an argument, you are actually given a pointer (aka. address) to the first character of a string. To see what is in a string, you must loop through every character of the string until you reach the null character.
Later in the lab, when we say that 2 keys match or equal each other, this means the entire strings are identical to each other. You cannot simply check if the pointer addresses match and must call this equals function to check.
Your task: Write a function equals that takes in 2 string pointers as arguments a0 and a1 and return in a0: 1 if the two strings are identical, 0 otherwise.
Part 2: Implement your Hash Table
To store your hash table, we will use an array, which we will call storearray in this lab. This array will store the key/value pairs that go in your table. The array is structured to have key/value pairs right next to each other. For example, index 0 stores a key, index 1 stores a value, index 2 stores a key, etc.
The array can store up to 64 key/value pairs, and both the keys and values are 1 word long. This means that storearray has a length of 128 words. You might notice that this is similar to how a 2D array is stored in memory.
This hash value from Part 1a is used to calculate the index of where your value will go. For example, CMPUT 229 will result in a hash of 23, which is used to calculate the index for storearray.
The index of the key in storearray is calculated using hash * 2. The index of the value in storearray is calculated using (hash * 2) + 1. For example, pointer to CMPUT 229 will be stored at index (23 * 2) = 46 in storearray and the value 154 will be stored at index (23 * 2) + 1 = 47 in storearray.
When both the key and value is the integer 0, this means that the entry is empty.
Once you have calculated the indices of the key and value in storearray, you can start to implement the 3 functions.
To insert a key/value pair, simply set the key and value in storearray.
To find a value pair, return the value in storearray that matches the given key. If the key/value pair doesn’t exist or if the keys don’t match, return -1.
To delete a key/value pair, set both the key and value in storearray to 0. If the key/value pair doesn’t exist or if the keys don’t match, return -1.
Hint: you only want to return a found entry and delete an entry if the keys actually match! Sometimes, the hash can be the same for two different keys.
Your tasks: Write a function insert that takes the above arguments plus the value in question in a2 and inserts the key/value pair in the hash table.
Write a function find that takes the above arguments and returns the value in the hash table in a0. If the entry does not exist, return -1 in a0.
Write a function delete that takes the above arguments and removes the key/value pair in the hash table by setting both the key and value to 0. If the entry in question was found and deleted, return 0. If the entry does not exist, return -1.
Part 3: Oh no, collisions!
By this point, you might have noticed a problem: what happens if 2 keys have the same hash? This is known as a collision. We will be using a linked list to solve this issue.
We will change the structure of the array to compensate for the linked list. Every key/value pair will be 3 words long rather than 2 with an additional space for a pointer to the next element.
We will refer to the pointer to the next element as next* for the rest of the section. Notice how the length of storearray is now 192 words. Because of this change in structure, we will now have to change how our functions work.
Since we are dealing with dynamic memory allocation, we have provided you with a function alloc in common.s that allocates a new 3-word area in memory. This function takes in no arguments and returns a pointer to a new element in a0. For the simplicity of this lab, you do not need to worry about deallocation or wiping the memory. Our test cases will not overflow over the provided buffer.
If you try to insert a value, there are 3 possible cases:
- If
storearrayis empty at the entry, insert the value like you did in part 2 while compensating fornext*. - If
storearraycontains one entry (meaningnext*is a null pointer), allocate a new area in memory, insert the values there, and setnext*to the new area of memory that you allocated - If
storearraycontains more than one entry (meaningnext*is not a null pointer), allocate a new area in memory and insert the values there. Then, you must search through the list until you have found the end of the list (meaning you have found a null pointer). Set that null pointer to the new area of memory you have allocated.
If you try to find a value, you will similarly first check storearray for an entry. If it exists, return it like normal. If not, search through the list until you either find the entry you are looking for or the end of the list.
If you try to delete a value, you must first locate the value you are looking for, similar to find above. If your value wasn’t found, return -1. Otherwise, there are 3 cases you must compensate for:
- If the entry is in
storearray, copy the 3 elements (key, value, pointer) from the element atnext*directly into the hash table. - If the entry is in
storearrayand there is no next element (next*is a null pointer), set the key and value to0. - If the entry is in an allocated piece of memory, copy
next*from the current entry to the previous entry.
It is highly recommended refer to the videos to ensure you understand how the 3 functions work.
Your tasks: Write functions insert_col, find_col, and delete_col to support collisions. Hint: copy your code for insert, find and delete as a base.
Testing your Lab
We have provided you with helper functions to help test and debug this lab. There are two extra files in your repo: playground.s and playground_col.s for testing Part 2 and Part 3 respectively. Each contain an argument a0 which is a pointer to storearray. You can call any of your respective functions within those files. They will then output a representation of the array to the console. Please note that you will have to check the return values of your function yourself.
The tests provided to you are not extensive! You must test on your own to ensure your code is correct.
The following are also some strings that hash to the same value. You can use this to test Part 3.
- “CMPUT 229” and “ENGL 107”
- “ACCTG 311”, “BIOL 108”, and “STAT 254”
Assumptions and Notes
- Each integer and address has a length of 1 word.
- Values cannot be negative.
-1is used to represent an error. Values however could be 0. - The length of
storearrayis 128 words in Part 2 and 196 words in Part 3. - For all strings, you are allowed to store the pointers of each string given to you directly in your tables. You do not need to copy any strings and can assume that the pointers will be valid throughout the lab.
- For Part 2, there will be no collisions. We won’t insert two entries with the same key during our testing. ex. we won’t call
insertwith the key “CMPUT 229” more than one time. - For Part 3, we will ensure all test cases does not overload the buffer given using
alloc. As long as you are not unnecessarily allocating memory, your code will pass the tests. - You can write as many functions or procedures as necessary as long as they do not begin with
main,testorplayground. - Remember to use all register conventions, even in
playground. - Some students reported issues using the
beqzinstruction in RARS. If you find your code is buggy or doesn’t run properly, usebeq zeroinstead.
Conclusion
Congratulations! You just implemented a simple, yet useful hash table in RISC-V assembly.
Notice that the time complexity for this implementation of hash table is O(1), or constant time, in an ideal (average) case. The ideal case for hash tables is for there to be no collisions. Typically, it is an efficient data structure for storing key/value pairs. However, the worst cases will occur when collisions are high, or when multiple keys hash to the same value. In those cases, the linked list will continuously grow. The time complexity in the worst case is O(n), or linear time.
Also, you might notice that the hashing algorithm you choose might have a huge impact on the number of collisions. Generally, we want to keep collisions low, so choosing a good and random hash function is important.
Resources
Marking Guide
Assignments too short to be adequately judged for code quality will be given a zero for that portion of the evaluation.
- 10% for correctly implementing
hash. - 5% for correctly implementing
equals. - 25% for correctly implementing
insert,find, anddelete. - 40% for correctly implementing
insert_col,find_col, anddelete. - 20% for code cleanliness, readability, and comments
Submission
There is a single file to be submitted for this lab. hashtable.s should contain the code for all 8 functions.
- Do not add a
mainlabel to this file. - Do not modify the line
.include "common.s". - Keep the file
hashtable.sin theCodefolder of the git repository.