DISCLAIMER: This page contains math equations and images. If you cannot see either of them on this page, try loading the page on a different web browser.
This lab introduces the Graphics Library for RISC-V (GLIR) and provides practice implementing algorithms in RISC-V assembly code. In particular, you will be implementing the A* (A-star) algorithm for solving pathfinding problems.
Pathfinding algorithms are designed to find the shortest path from a source to a destination within an environment. They are fundamental tools in Computing Science and have applications in Artificial Intelligence (AI), video games, real-time route planning (Google Maps), and more. There are many different pathfinding algorithms. Although they all try to find the shortest path between two points, they differ in how they search the environment. A pathfinding visualizer allows us to see how pathfinding algorithms work by visualizing how the algorithms explore the environment. This lab will implement a simpler version of the pathfinding visualizers that can be found online. Here are some examples of pathfinding visualizers that you can find online.
This lab implements only one pathfinding algorithm, A*. A feature of A* is the use of heuristic functions, which estimates the distance to the destination. As long as the heuristic function does not overestimate distances, A* is guaranteed to find the shortest path (if it exists). The use of heuristic functions allows A* to prioritize its search on seemingly shorter paths, and thereby avoid wasting time and memory on paths that seem less promising.
Write a RISC-V program that implements A* and visualize how it searches the environment for the shortest path between a given source and a given destination on the terminal with GLIR. Your program should handle different environments (e.g. size, obstacles), and different start and end points. Your program should be as efficient as possible (more on this later).
GLIR is a collection of subroutines to emulate graphics in a terminal. It is capable of printing characters with foreground and background colours to the terminal window.
GLIR works by printing cells onto the terminal window. The terminal window is represented as a cell of rows and columns:

The tuple representing a position on the cell is (R, C) and not (C, R) -- where R represents a row and C a column. This is because terminals were designed to print text top to bottom, left to right. The origin (0, 0) is at the top left of the terminal window:
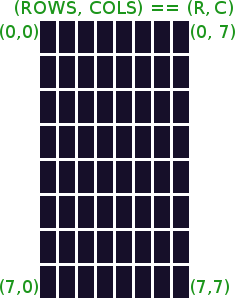
Note: The screen above is a square cell, but terminals and fonts are not square, thus a square cell renders a rectangular shape.
The code provided in the common.s file calls two GLIR
functions. One before the visualizer is called, and one after.
GLIR_Start: This function must be called before the visualizer to prepare the
terminal for the visualizer:
GLIR_End: This function must be called after the visualizer to revert the
terminal back to its default state:
For colours, GLIR uses the ANSI escape codes, which are a set of codes that can be used to change the color of the text or background of the terminal. GLIR abstracts away these ANSI escape codes and allow the user to simply select the desired color code from a 256-color lookup table:
| Standard colors | High-intensity colors | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 216 colors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | ||||||||||||||||||||||||
| 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | ||||||||||||||||||||||||
| 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 | 104 | 105 | 106 | 107 | 108 | 109 | 110 | 111 | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | 120 | 121 | 122 | 123 | ||||||||||||||||||||||||
| 124 | 125 | 126 | 127 | 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | ||||||||||||||||||||||||
| 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 168 | 169 | 170 | 171 | 172 | 173 | 174 | 175 | 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 | 184 | 185 | 186 | 187 | 188 | 189 | 190 | 191 | 192 | 193 | 194 | 195 | ||||||||||||||||||||||||
| 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 204 | 205 | 206 | 207 | 208 | 209 | 210 | 211 | 212 | 213 | 214 | 215 | 216 | 217 | 218 | 219 | 220 | 221 | 222 | 223 | 224 | 225 | 226 | 227 | 228 | 229 | 230 | 231 | ||||||||||||||||||||||||
| Grayscale colors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
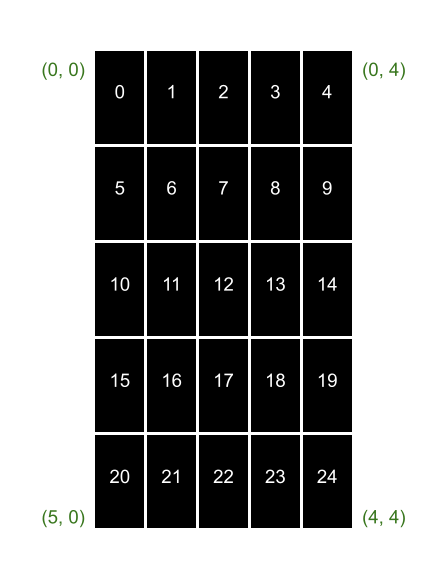
In this lab, you will implement and run A* on maps composed of equally-sized cells, where is the number of columns and is the number of rows. It is guaranteed that and . Each cell can either be a grass cell (green), the start (red), the goal (yellow), or a water cell (light blue). Each cell is associated with a unique non-negative integer, or cell number. The uppermost left cell is numbered 0, and increments by one each time we move one cell to the right. If we reach the end of the row, we wrap to the left most cell one row below, and continue.
From any cell, we can only move into a cell that is immediately to the left, right, top, and bottom with a distance of one (1) unit (we will call these the adjacent cells). We cannot move into a water cell, nor can we move off the map.
Below is a picture illustrating the environment:
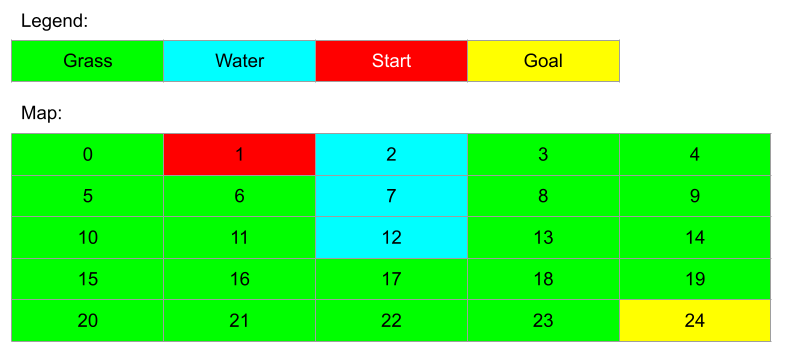
From cell 1, we can move into cells 0, and 6. We cannot move up because we will move off the map; we cannot move into cell 2 because it is a water cell; and we cannot move into cell 5 because it is diagonal from cell 1.
In this environment, paths are defined between two cells. Paths must obey the environment constraints described above. That is, a path is valid if all the cells on the path are grass cells, and, informally, you can trace the path with a pen from start to finish without lifting your pen, and without crossing into diagonal cells. For example:
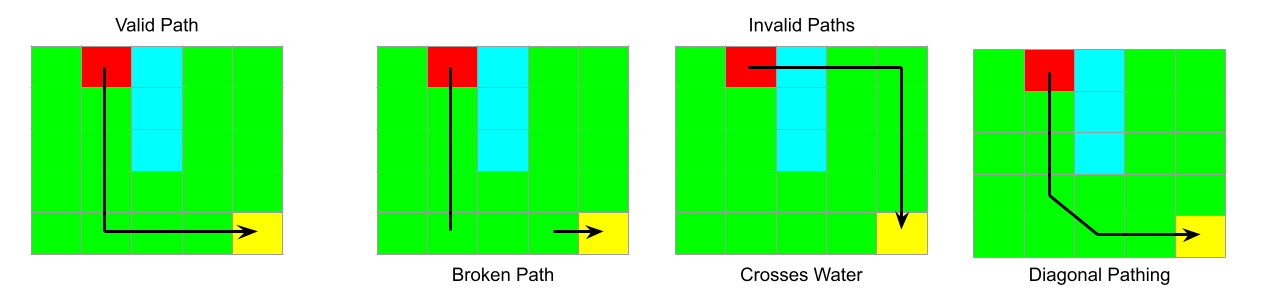
A valid path can also be represented as a sequence of cell
numbers of the cells that makes up the path. For example, the valid
path in the image above can be represented as
1, 6, 11, 16, 21, 22, 23, 24
, which means that the path starts at cell 1, goes through cells
6, 11, 16, 21, 22, 23 (in that order), and terminates at cell 24.
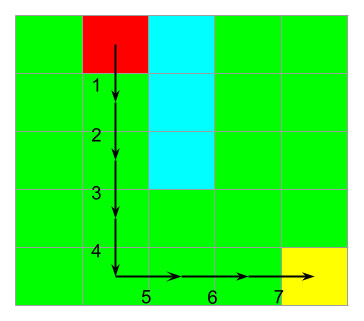
In the environment for this lab, the distance between adjacent cells is one (1) unit. The distance of a path is defined to be the distance between the first cell and the last cell of the path. For a path with cells, we have to move times to travel from the first cell to the last cell on the path. Therefore, the distance for a path with cells is units.
For example, there are eight cells in the path shown in the image
below: 1, 6, 11, 16, 21, 22, 23, 24, and its distance
is units.
This section introduces A* in the context of the environment described above, and also introduces some A* terminology.
To store information, A* uses two lists:
There are many ways to implement the closed list and the open list. In a later section, we will detail how they should be implemented in this lab.
The previous section assumed that A* has already found a valid path from the start to a cell . This section lifts this assumption to discuss how A* actually finds such valid paths.
The search begins with A* recording the parent, g, and h for the start cell. The parent of the start cell is defined to be itself, thus g is zero. The h of a cell is computed by an heuristic function. After A* has recorded the parent, g, and h for the start cell, the start cell has been visited. A* now visits the adjacent cells of the start cell, setting their parent as the start cell, their g as one, and their h computed using the heuristic function. After visiting all the adjacent cells of the start cell, the start cell is considered expanded. A* continues to expand visited cells until it expands the goal, in which case a solution path is found, or when there no more visited cells to expand, in which case no solution paths are found.
A* prioritizes expanding cells with the shortest estimated path from the start to the goal by expanding the cell with the smallest f first. Open List details how to efficiently find the cell with the smallest f among all the visited cells.
There can be multiple paths from the start cell to a cell . Thus, there migh be multiple parents and values of g for . The Closed List of A* keeps only the parent and g of for the shortest path from the start to .
Below is the pseudocode for A*:
A* Search Initialize the open list Initialize the closed list Visit the start cell Insert the start cell into the open list while the open list is not empty let be the cell with the least f pop from the open list if is the goal stop the search Redraw the cell corresponding to with the color gray // Expand generate all 4 adjacent cells of for each adjacent cell, , of if is a water cell or is off the map skip else .parent = // dist(start,) = dist(start,) + dist(,) // In our environment, dist(, ) = 1 .g = .g + dist(, ) // Estimate the distance from to .h = heur(, ) // We have not explored yet if is not in closed list add to the closed list (closed list)..parent = .parent (closed list)..g = .g (closed list)..h = .h add to the open list Check and maintain heap property of the open list // We have found a shorter path to if is in the closed list AND .g < (closed list)..g update .parent, .g, and .h in the closed list Check and maintain heap property of the open list end A* Search
The part in the pseudocode that is highlighted in yellow draws updates of the map to the terminal. Updating the terminal is discussed in detail here. The parts in the pseudocode that is highlighted in green will be explained in a later section.
This lab requires that your implementation of A* visits adjacent cells in the following order: left, right, top, and bottom.
In this lab, the internal representation of the entire map is stored in
the map buffer. The map buffer is an 1D array of 32-bit integers
where the 'th element of the array contains the
value 1 if the 'th cell is a water cell and it
contains the value 0 otherwise. The common.s file
pre-allocates the map buffer and passes the pointer to the map buffer as
an argument to the student's pathFinder procedure.
Another argument to the pathFinder procedure is a pointer
to the water array. The water array is an array of 32-bit integers
where each integer is the cell number of a water cell in a
particular map. The cell numbers in the water array are not
guaranteed to be sorted in any particular order.
This lab implements the closed list as an 1D array of structures,
described below.
The common.s file pre-allocates enough space for each cell
to have an entry in the closed list, and will pass the pointer to the
closed list as an argument to the student's pathFinder
procedure.
Each entry in the array will be a struct containing three 32-bit
integers in the following order: parent, g, h. For
simplicity, the cell number of a cell and the index of its corresponding
entry in the closed list must be the same (e.g. the corresponding entry
of cell 7 should have an index of 7 In the closed list).
Your code must initialize the open and closed lists before running the
A* algorithm.
This initialization is described in this section.
A parent of -1 indicates that the cell has not been
visited yet.
If a cell has been visited, the solution must record its parent,
g, and h in the corresponding entry of the cell.
The parent and g of a cell must be updated whenever A*
finds a shorter path to the cell than the current known path.
The image below summarizes the in-memory representation of the map buffer, the water array, the closed list, and the open list.
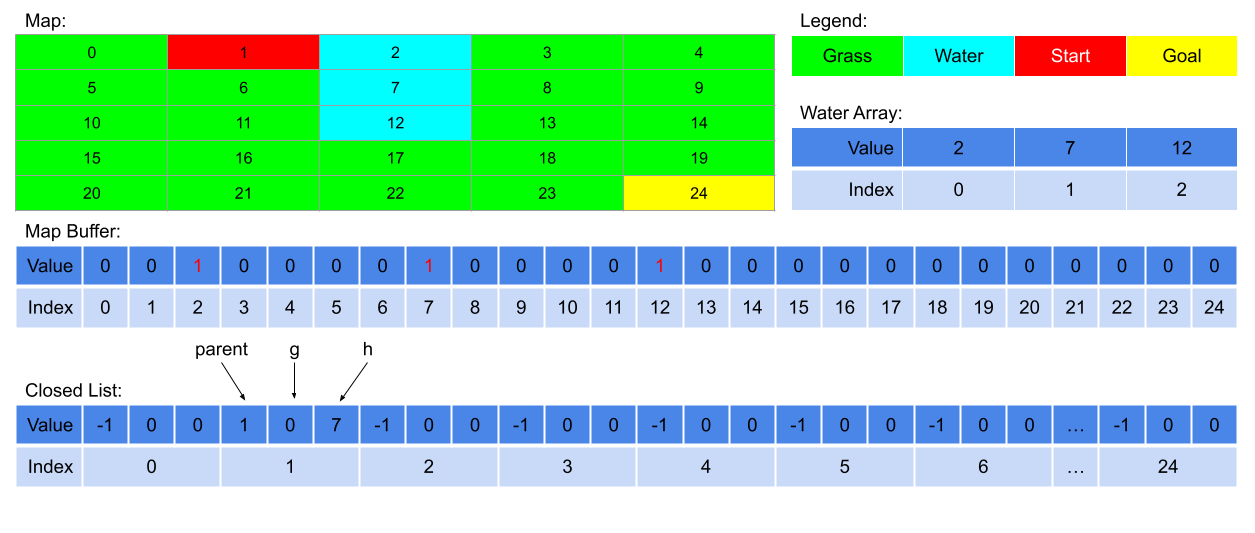
The open list keeps track of the cells that are visited but that are not expanded yet. As seen in the A* pseudocode, A* does this by adding a cell to the open list whenever it visits the cell for the first time, and removing a cell whenever it expands the cell. In every iteration of the search, A* expands one cell, and visits a maximum of four cells. Hence, operations such as insertion and deletion from the open list needs to be efficient. For this reason, this lab implements the open list using a min-heap.
The heap data structure is a complete binary tree that satisfies the heap property. In memory, this lab represents such a binary tree using an 1D array of 32-bit integers, where the root node has an index of zero. For any given node in the tree with index , its left child has an index of , and its right child has an index of . For the binary tree to satisfy the heap property of a min-heap, the root node must have the smallest key, and, for any given node, its key must be less than or equal to the key of its children (if any). The key is simply a value used to order the entries in the heap. In this lab, the entries in the heap are cell numbers, and the keys are the f value of the cells.
The image below shows two trees with their respective in-memory representation directly below their tree representation. The number inside the tree nodes are keys. The tree on the left satisfies the min-heap property while the tree on ther right does not because the key of its root node is greater than the key of its left child.
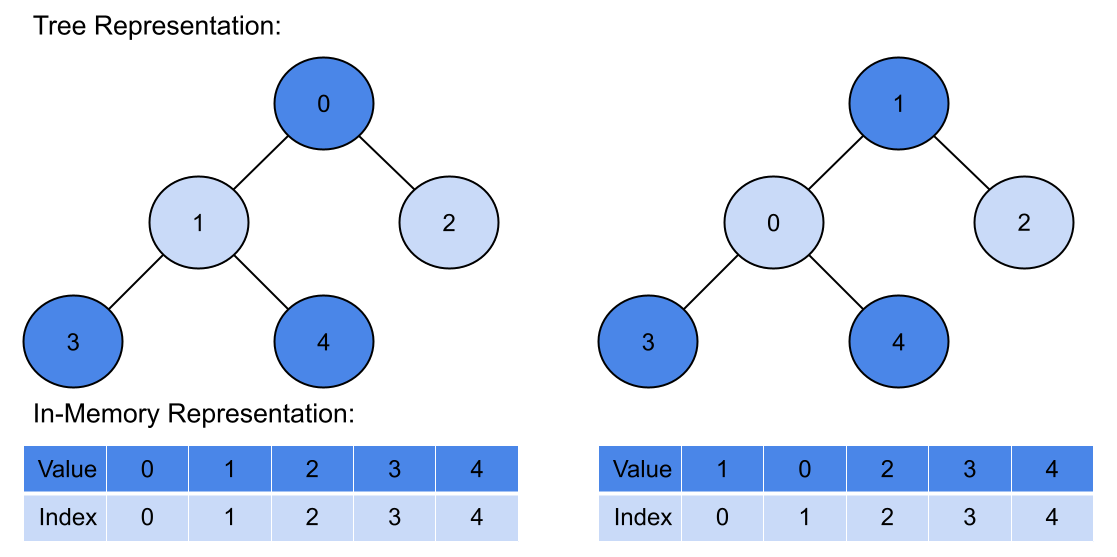
The heap property must be checked for every insertion, deletion, or change of the key of an element. If the heap property no longer holds after a change, the heap must re-arrange the elements such that the heap property holds again (this action is called heapifying the tree/array). This requirement is highlighted in green in the A* pseudocode above.
The file heapq.s provides code for following heap operations that should be used for the solution for this lab:
insert:
a0: pointer to the open lista1: pointer to the closed lista2: the cell number of the cell to inserta2
into the open list. Maintains the heap property based on the
f values of the cells.popMin:
a0: pointer to the open lista1: pointer to the closed lista0:
The cell number of the cell with the least f
value in the open list
minHeap:
a0: pointer to the open lista1: pointer to the closed lista1 into a heap in
place based on the f values of the cells.
Although having a high-level understanding of the heap data structure
and the heap operations is sufficient for students to complete the lab,
it is strongly recommended that students take a look at
heapq.s and try to understand the RISC-V implementation
of the heap data structure and the heap operations.
common.s passes the pointers to the map buffer, the open
list, and the closed list to pathFinder as arguments.
Sufficient space is allocated for each array, but the three arrays
are not initialized.
You must initialize the the open list and closed list in
your aStar function as follows:
-1, 0, 0.
A heuristic function estimates the distance to go between a given cell and the goal. In this lab we will use the Manhattan distance as the heuristic function. The Manhattan distance measures the sum of the absolute differences between the coordinates of two points. As described in Drawing the map we can identify each cell with a tuple (R, C). The Manhattan distance between two cells is defined as: . In other words, it is the absolute difference between the row numbers plus the absolute difference between the column numbers. The image below demonstrates the calculation of the Manhattan distance between cells 1 and 24 on a 5-by-5 map.

As mentioned here, each cell in the map is represented with a unique integer. GLIR however, prints to terminal using rows and columns. For the convenience of converting between the two systems of representation, align cell 0 with the cell located at (0, 0) on the terminal window.
In this lab all grass cells will be colored green, all water cells will be colored blue, the start will be colored red, and the goal cell will be colored yellow. Use color code 10 for green, color code 14 for blue, color code 9 for red, and color code 11 for yellow.
During the search, color any expanded node in grey. If a solution is found at the end of the search, you must color the solution path with purple. Use color code 8 for grey and color code 13 for purple.
There are multiple ways to display updates on the screen. This lab uses the following method:
All the steps can be achieved using the
GLIR_PrintRect subroutine.
GLIR_PrintRect
Below is the function specification of the GLIR_PrintRect
method is the GLIR library.
GLIR_PrintRect
Arguments:
a0: Row of the top left corner
a1: Col of the top left corner
a2: Signed height of the rectangle
a3: Signed width of the rectangle
a4: Color to print with
a5: Address of null-terminated string to print with; if 0 then uses
the unicode full block char (█) as default
Returns:
None
Prints a rectangle using the (Row, Col) point as the top left corner having
width and height as specified. Supports negative widths and heights.
Specifying a height and width of 0 will print a rectangle one cell high by
one cell wide.
To draw the initial map,
we recommend that you use the GLIR_PrintRect method to
draw the cells of the map one by one. You can redraw a cell with a
different colour by calling the GLIR_PrintRect method with
the coordinates of the cell and the desired colour.
Here is the general flow of the visualizer.
The video below is a short demonstration of how the map, and the states of the closed list and the open list changes as A* searches the environment. This video is created by screen recording slides 47-60 in the presentation for this lab.
When testing, provide the map specification file as program arguments
using the pa commandline option of the RARS simulator.
For example:
rars pathFinder.s pa test-map-1.txt
This output has been slowed down on purpose. The speed of the animation in the example output may not match your output. This is perfectly fine as the speed of the animation will vary depending on the speed of your computer and operating system.
We define the following global variables in common.s:
ROWS: the number of rows in the mapCOLS: the number of columns in the mapGREEN: the color code for greenBLUE: the color code for blueYELLOW: the color code for yellowRED: the color code for redGREY: the color code for greyPURPLE: the color code for purple
heapq.s also provides the current size of the heap (open
list) as a global variable:
SIZE: the size of the open listcommons.s will always set the dimension of the terminal
to be the same as the dimension of the input map.
The solution must follow the RISC-V register saving/restoring calling conventions .
The solution for this lab is implemented in pathFinder.s.
which must implement the following functions:
pathFinder:
a0: pointer to the open lista1: pointer to the closed lista2: pointer to the map buffer.a3: the cell number of the start cella4: the cell number of the gaol cella5: pointer to the water array.a6: length of the water arraya0: 1 if a solution path is found, 0 otherwise.
This is the entry point of the pathfinding visualizer. This method should:
buildMap:
a0: pointer to the water array.a1: length of the water arraya2: pointer to the map bufferdrawMap:
a0: pointer to the map buffer.a1: the cell number of the start cella2: the cell number of the goal cellaStar:
a0: pointer to the open list.
a1: pointer to the closed list.
a2: pointer to the map buffer
a3: the cell number of the start cella4: the cell number of the goal cella0: 1 if a solution path is found, 0 otherwise.
drawSoln:
a0: pointer to the closed list.a1: the cell number of the start cell.a2: the cell number of the goal cell.isWater:
a0: pointer to the map buffer.a1: the cell to checka0: 1 if the cell is a water cell, 0 otherwise.
manhattan:
a0: the cell number of cell A
a1: the cell number of cell Ba0: the Manhattan distance between cell A and
cell B
This is a visual lab. Thus, it may be difficult to
test the non-visual functions: buildMap,
isWater, and manhattan.
These functions are tested automatically by
common.s when you run pathFinder.s.
rars pathFinder.s pa <map-spec-file.txt>.
rars pathFinder.s pa <map-spec-file.txt>.
ssh into a lab machine. Instructions to access the
lab machines can be found
here. Follow the Linux/macOS instructions.
rars pathFinder.s pa <map-spec-file.txt>.
We provide a Python script (<REPO_ROOT>/map-builder-tool/map_builder.py)
that allows you to interactively create maps to test your solution. To
use the tool, cd into the map-builder-tool
directory and install the required packages:
pip install -r requirements.txt. You can then run the tool
by executing python3 map_builder.py, and follow the
instructions in the program to create maps interactively.
When you click on the "Get Input File" button in the program, it generates a file with the following format:
ROWS COLS START GOAL the cell number of the water cells (if any) separated by whitespaces
For example, the following input file:
5 5 0 4 2 7 12 17
represents a map that has 5 rows and 5 columns, where cell 0 is the
start, cell 4 is the goal, and cells 2, 7, 12, and 17 are
water cells.
Input files must have the empty line at the end of the
file.
commons.s will otherwise throw an 'Invalid
file contents' error.
The "Get Input File" button will also print the location of the input file to the terminal that you used to launch the program. Please also refer to the same terminal for other program messages.
Here is a sample execution of the map builder tool on an Intel machine running Debian 12 with GNOME 43.9 as the desktop environment:
drawMap and test it using the map
builder tool.
aStar and drawSoln last.
Assignments too short to be adequately judged for code quality will be given a zero.
drawMap, A*,
and drawSoln.
buildMap, isWater, and
manhattan procedures.
a0 return value from the
pathFinder procedure.
Ensure that your solution works in the lab machines because it will be graded using the lab machines.
There is one file to be submitted for this lab:
pathFinder.s should contain the code for A* search and
visualizing the map. You can add additional functions as you see fit.
main label to this file..include "common.s".common.s file.